TIME_WAIT与Http的Keep-Alive
背景
虽然上一次服务器TIME_WAIT连接过多导致报警后,解决方案初步拟定,但是还有一个疑问:线上的服务器架构是前端 -> nginx -> server的模式,但是nginx服务器并没有触发报警,仅仅后端server服务器触发了报警。
况且是一台nginx服务器负载均衡了多台server服务器,当时每台server服务器均触发了6000的连接数阈值,但nginx上仅仅有三千多的连接数。查看连接数命令如下:
1 | [nginx@hd2-cil-rs-nginx-01 ~]$ netstat -n | awk '/^tcp/ {++state[$NF]} END {for(key in state) print key,"\t",state[key]}' |
1 | [nginx@hd2-cil-rs-nginx-01 ~]$ ss -s |
重新审视TCP的四次挥手流程,TIME_WAIT状态是TCP连接的主动关闭方会有的状态,在发出最后一个ACK包之后,主动关闭方进入TIME_WAIT状态,为了防止在端口被复用时收到了迷途包导致数据错误的情况。
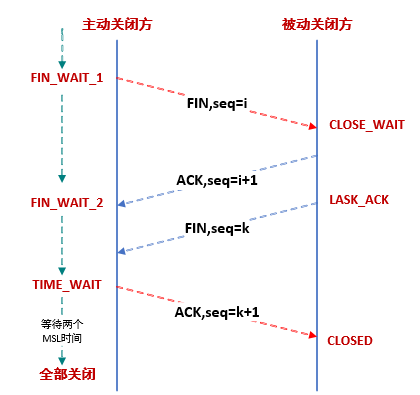
也就是说虽然请求是前端 -> nginx -> server的流程,但是大多数请求是被server服务器主动关闭,导致server服务器的TIME_WAIT状态连接远远多于nginx服务器。具体原因,则需要通过抓包来观测http请求的关闭流程了。
TIME_WAIT的危害
TIME_WAIT状态是TCP链接中正常产生的一个状态,TIME_WAIT状态过多会存在以下的问题:
- TCP连接的
TIME_WAIT状态结束之前,该端口号将一直无法释放。如果请求并发量很大,TIME_WAIT状态的TCP连接会把系统所有的可用端口占用,最终服务器端口耗尽无法建立新TCP连接 - 大量的
TIME_WAIT状态也会系统一定内存和cpu资源
对于问题1,只有作为client时的TCP连接才会占用可用端口的情况,如果作为server端的TCP连接处于TIME_WAIT状态,只会占用监听端口,只需要注意Too many open files的问题,修改文件句柄限制即可;而问题2问题不大,提高服务器配置即可。
前端请求nginx
从前端请求到nginx服务器的http请求,查看nginx日志几乎都是HTTP1.1,而线上nginx默认的HTTP长长连接配置是keepalive_timeout 65即HTTP长连接超时时间为65秒,HTTP长连接超时后,则会由nginx主动关闭连接,而该TCP连接也会进入TIME_WAIT状态。
如下图,使用Chrome浏览器发起长连接后,中途浏览器发起过一次心跳包(不同的客户端实现有所出入,例如Postman发起长连接后,会每秒发起一次心跳包),最终在65秒时由nginx端主动发起了TCP关闭。
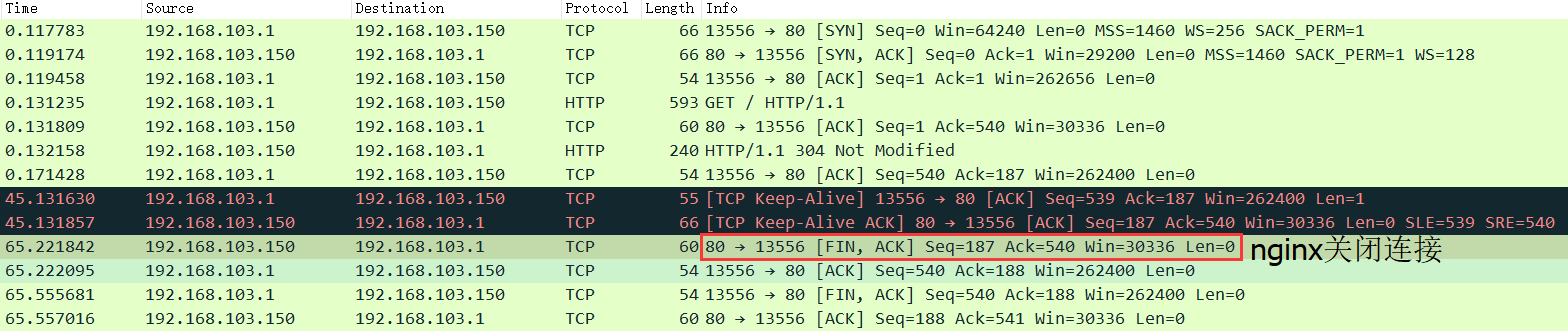
当然在实际使用场景下,很多用户从前端发起请求后,并不会在页面保持65秒之久,关闭页面或者浏览器后,则会由客户端主动发起TCP关闭,如下图。这时候该TCP连接在nginx服务器就会直接关闭回收,不会进入TIME_WAIT状态。

nginx中keepalive_timeout参数默认为65,修改为0则代表禁用keep-alive客户端连接,所有的HTTP连接均为短连接。前端客户端发起HTTP请求到nginx后,nginx返回的Response会添加Connection: close的HTTP Header通知客户端该HTTP连接已关闭,并且由nginx端主动关闭TCP连接,如下图。
1 | location / { |

因此强烈建议启用keepalive_timeout保持前端到nginx的长连接。如果使用HTTP短连接,当一个页面发起多个请求时,该每一个HTTP请求将会创建一个独立TCP连接,不仅耗时,而且还会使nginx服务器的TIME_WAIT连接暴增。
nginx代理后端
默认配置
线上nginx负责将请求负载均衡给各个后端server服务器,使用的配置如下。该配置下,nginx请求到server的HTTP请求均为HTTP/1.0,并且为HTTP短连接。
1 | upstream http_backend_8080 { |
通过查看HTTP报文请求,nginx请求到server的HTTP请求的Header中有Connection: close,即通知后端server在完成本次请求的响应后,断开连接。通过抓包发现,大多数情况下,是server端主动关闭连接,如下图。
因此前端发起的HTTP请求,通过nginx负载均衡到server后,都会对应一个server端的TIME_WAIT状态的TCP连接。

而在少数情况下,则由nginx端主动关闭连接,如下图:

综上,前端到nginx端默认使用的HTTP长连接,发起多次HTTP请求使用的同一个TCP连接;nginx负载到server时,则对应了多个HTTP短连接。大多数情况下由server端主动关闭连接,就导致server端的TIME_WAIT状态连接暴增。
HTTP1.1配置
修改nginx参数,代理连接使用HTTP/1.1时,实际效果与HTTP/1.0相同。
1 | upstream http_backend_8080 { |
大多数情况下,是server端主动关闭连接,如下图:

少数情况下,由nginx端主动关闭连接,如下图:

HTTP连接池配置
启用nginx的HTTP连接池后,nginx到server端的HTTP连接不再是朝生夕死的短链接,而是HTTP长连接,keepalive的时长由server端决定,例如springboot默认60秒。
1 | upstream http_backend_8080 { |
启用连接池后,HTTP连接创建后经过60秒才被server端主动关闭,可以减少大量的TCP连接创建和销毁。虽然依然是server端发起主动关闭,造成server端的TCP连接进入TIME_WAIT状态,但是TCP连接总数量大大减少,从而大幅降低了server端TIME_WAIT状态的TCP连接数量。

后端http调用
server端TIME_WAIT状态的TCP除了nginx负载均衡到server的HTTP请求,还有server端系统请求其他server端系统的HTTP请求。
无连接池
例如java端的HTTPClient库,在默认参数下不会使用HTTP连接池,发起一个HTTP请求后,通过抓包如下图,每个HTTP请求均为短连接,且会由请求端主动发起关闭连接,因此请求端的TCP连接会进入TIME_WAIT状态。

这种情况相当糟糕,因为后端系统之间的调用相当频繁,甚至前端的一个请求到后端时,后端需要发起多个HTTP请求调用其他系统才能完成,而每一次请求其他系统的HTTP请求都会导致一个TIME_WAIT状态的TCP连接。这时候如果前端请求QPS上升,则会导致该server服务器TIME_WAIT状态的TCP连接数量暴增。
有连接池
因此后端系统直接的调用也需要使用HTTP连接池,java端的HTTPClient库使用了HTTP连接池后,效果如下图,每个HTTP连接为长连接,并且会由被调用端主动关闭连接。不仅TCP连接数量大幅减少,而且TIME_WAIT状态也转嫁到被调用端,而非全部集中到调用端了。

总结
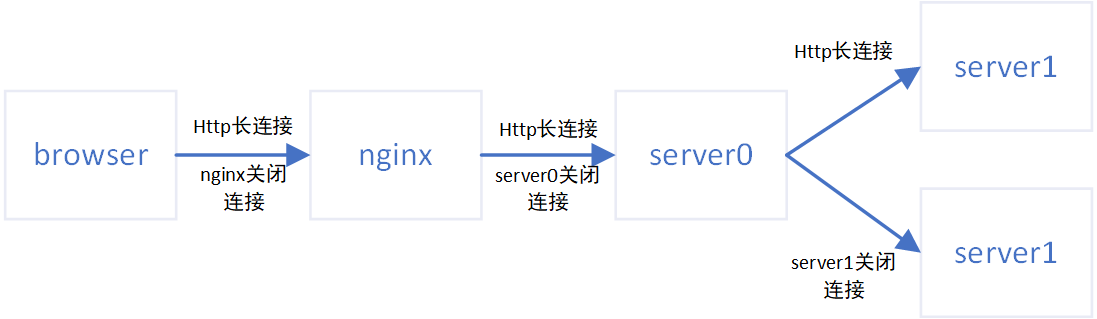
优化前,除了前端到nginx使用HTTP长连接,其他部分例如nginx到server端,后端应用之间调用都使用的HTTP短连接,如下图,最终当前端QPS上升时大量的HTTP短连接由server0服务器发起关闭,造成该服务器TIME_WAIT状态的TCP请求数量暴增触发阈值报警。
显而易见,server0服务器成为了TCP连接数量的瓶颈。

优化后,所有端到端的HTTP连接均改为HTTP长连接,TCP连接的创建和销毁数量陡然下降,并且HTTP连接也不再全由server0服务器关闭,server0服务器只负责nginx代理到server端的HTTP连接关闭,从而进一步减少了该机器的TIME_WAIT状态的TCP请求数量。