记一次TIME_WAIT导致连接数报警
背景
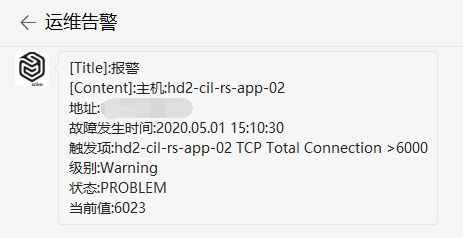
公司监控报警,提示线上服务器的TCP连接数超过警告阈值。报警的几个机器原先的业务量请求量并不大,所以预设的报警阈值并不高只有6000,突然报警有点措手不及,于是先登录服务器把当前的所有连接情况打印下来统计分析。
1 | [webapp@hd2-cil-rs-app-02 ~]$ netstat -natp > tmp |
原因分析
TCP连接数量暴涨,初步怀疑如下:
- 某应用的数据库连接泄漏,使用后数据库连接未释放;
- 业务场景发生变化,前端用户暴涨,导致请求量暴涨;
如上使用netstat命令将所有连接状态打印下来后,当成CSV格式导入Excel,借助Excel的统计能力来查看连接状态。
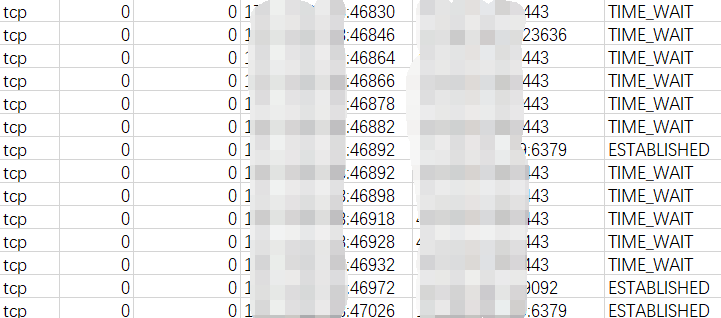
对所有的TCP连接的远程ip端口号进行统计后,得出下图饼状图,无论是Redis、Mysql还是MongoDB的连接,连接数量都很正常,未出现数据库连接泄漏的情况,占用比例最高的就是饼状图中银色部分,为内部几个应用之间的http调用,合计569个http连接,占总比的11%。
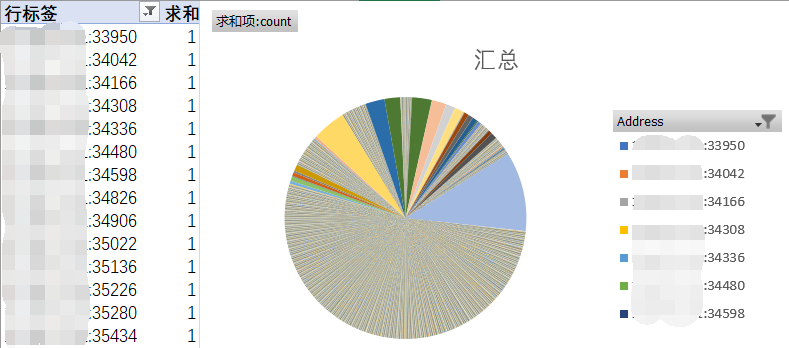
再对所有TCP连接的本地ip端口号进行统计后,得出下面的饼状图,占比最高的蓝色部分为nginx代理到某个应用的http连接数量,一共有1727个http连接,占总比的32%。
通过这两个饼状图,再结合系统监控的QPS统计图,可以分析出是由于QPS请求上升导致的连接数量暴涨触发了监控报警。
连接状态分析
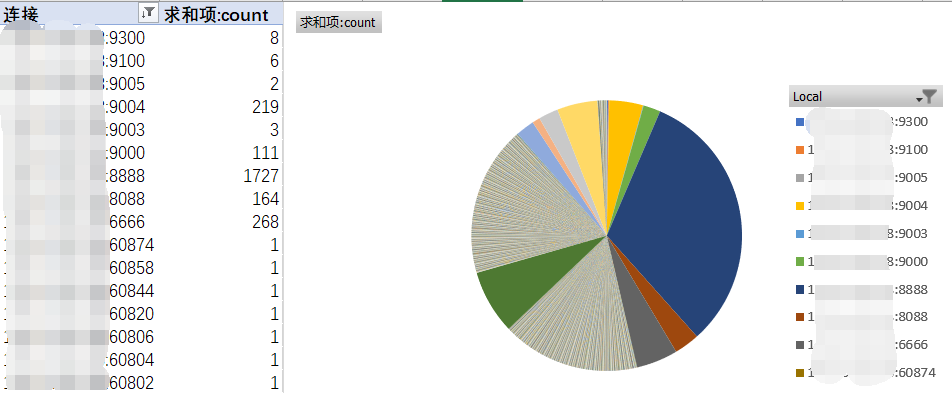
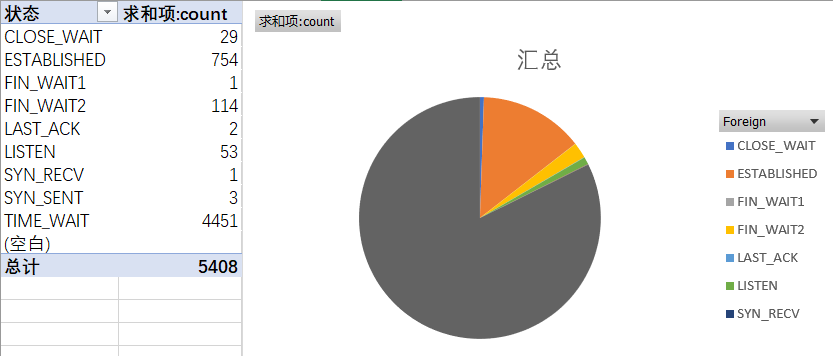
在上一步分析连接占比时,发现有大量的连接状态处于TIME_WAIT,于是再针对连接状态进行统计,得出下面的饼状图,共计5400个连接,有4451连接处于TIME_WAIT状态。
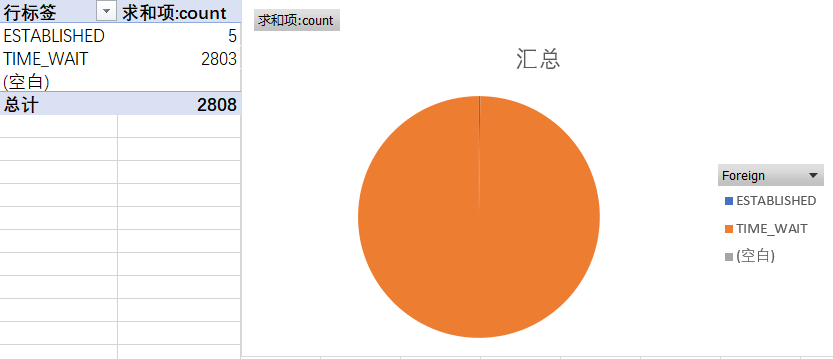
进一步分析,筛选出从nginx代理到后端应用的连接,得出下面的饼状图,2808个代理连接中有2803个处于TIME_WAIT状态。
综上所得,虽然报警TCP连接过多,但实际上处于使用中的连接数量占少数,绝大多数连接都处于TIME_WAIT状态。
TIME_WAIT
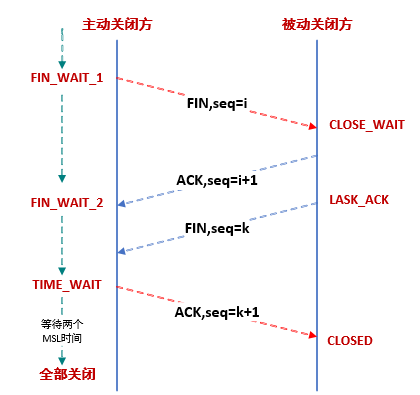
TCP数据包可能由于路由器异常而迷路,在迷路期间,数据包发送方可能因超时而重发这个包,迷路的数据包在路由器恢复后也会被送到目的地,这个迷路的数据包就称为Lost Duplicate。在关闭一个TCP连接后,如果马上使用相同的IP地址和端口建立新的TCP连接,那么有可能出现前一个连接的迷路重复数据包在前一个连接关闭后再次出现,影响新建立的连接。为了避免这一情况,TCP协议不允许使用处于TIME_WAIT状态的连接的IP和端口启动一个新连接,只有经过2MSL的时间,确保上一次连接中所有的迷路重复数据包都已消失在网络中,才能安全地建立新连接。
TIME_WAIT状态是TCP连接的主动关闭方会有的状态,在发出最后一个ACK包之后,主动关闭方进入TIME_WAIT状态,为了防止在端口被复用时收到了迷途包导致数据错误的情况。
对于TIME_WAIT状态,下面3个参数可以影响:
net.ipv4.tcp_tw_reuse:表示开启重用。允许将TIME_WAIT状态的连接重新用于新的TCP连接,默认为0,表示关闭;net.ipv4.tcp_tw_recycle:表示开启TCP连接中TIME_WAIT状态的连接的快速回收,默认为0,表示关闭;net.ipv4.tcp_fin_timeout:对于本端断开的连接,TCP保持在FIN_WAIT_2状态的时间。对方可能会断开连接或一直不结束连接或不可预料的进程死亡,默认值为 60 秒;
1 | [root@VM_0_10_centos ~]# cat /proc/sys/net/ipv4/tcp_tw_reuse |
实际上,上述3个参数中,net.ipv4.tcp_tw_reuse触发条件比较苛刻,需要远程IP和端口号都相同的情况下,才能将该TIME_WAIT状态的连接重新使用,因此即使启用了该功能,实际效果也不佳;而net.ipv4.tcp_fin_timeout则是个只读参数,修改了也没有任何效果;唯一有显著效果的参数只有net.ipv4.tcp_tw_recycle,但该功能风险较高,可能会导致大量TCP连接错误。
测试参数效果
发起一次请求后,通过netstat查看连接状态,发现刚刚的请求连接均处于TIME_WAIT状态,并且显示还需要58秒的时间才能回收该连接。
1 | [root@VM_0_10_centos ~]# netstat -nato | grep 4000 |
编辑文件/etc/sysctl.conf,添加或修改以下参数:
1 | net.ipv4.tcp_tw_reuse = 1 |
然后执行命令使sysctl.conf的参数生效:
1 | [root@VM_0_10_centos ~]# /sbin/sysctl -p |
1 | [root@VM_0_10_centos ~]# cat /proc/sys/net/ipv4/tcp_tw_reuse |
这时候再发起一次请求后,通过netstat查看连接状态,发现刚刚的请求连接均处于TIME_WAIT状态,而回收时长只有不到1秒的时间,即TIME_WAIT状态的连接被立即回收释放了。
1 | [root@VM_0_10_centos ~]# netstat -nato | grep 4000 |
建议方案
对于生产环境,并不建议通过修改net.ipv4.tcp_tw_recycle来快速回收TIME_WAIT连接,而是通过下面两种方案来减少TCP连接的创建和回收:
- nginx反向代理启用http连接池
- 应用内部调用启动http连接池
- 集群扩容增加负载节点
nginx启用http连接池
上述分析中,有2800个连接为nginx代理的http连接,且几乎都处于TIME_WAIT状态,如果启用nginx的http连接池,则可以直接避免这2800个连接,总连接数量瞬间减少一半。
1 | upstream http_backend_4000 { |
针对上诉场景的,我们需要使用nginx upstream keepalive来优化,配置如下:
1 | upstream http_backend_4000 { |
通过ab创建1000个线程请求10次,对nginx启用http连接池前后进行压测。
1 | ab -n 1000 -c 10 'https://127.0.0.1:443/' |
未启用http连接池时,压测后nginx创建了1000个TCP连接,并且压测结束后,这1000个连接全部处于了TIME_WAIT状态等待60秒回收。
1 | [root@VM_0_10_centos nginx]# netstat -nato | grep '127.0.0.1:4000' > tmp |
1 | tcp6 0 0 127.0.0.1:4000 127.0.0.1:56758 TIME_WAIT timewait (45.98/0/0) |
而启用了http连接池时,压测后nginx仅仅创建了10个tcp连接,并且压测结束后,这10个连接依然处于使用中,等待下次请求重复使用。
1 | [root@VM_0_10_centos nginx]# netstat -nato | grep '127.0.0.1:4000' > tmp2 |
1 | tcp6 0 0 127.0.0.1:4000 127.0.0.1:36488 ESTABLISHED off (0.00/0/0) |