背景
线上应用需要进行一个涉及600W数据的操作,之前我们应用从来没有一次性应对这么大量的数据,最多就一次数十万而已。结果,这次600W的数据操作引起了生产事故,直接导致应用不可用长达半小时之久。
OOM
晚上九点半,监控告警提示线上应用宕机。紧急排查发现应用的的进程已经不在了,怀疑是因为内存占用过多导致被操作系统杀进程了。接着查看操作系统日志,如下,果然发现是因为内存占用高达8G而被系统直接杀进程。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| [webapp@hd2-cil-rs-app-01 ~]$ dmesg
.
.
.
[38617319.591980] [13605] 0 13605 35957 340 71 0 0 sshd
[38617319.591982] [13607] 10006 13607 35957 361 67 0 0 sshd
[38617319.591984] [13608] 10006 13608 28879 143 14 0 0 bash
[38617319.591986] [14164] 10006 14164 2032213 1048193 2198 0 0 java
[38617319.591988] [14784] 10006 14784 30864 447 18 0 0 htop
[38617319.591989] [14802] 5000 14802 20750 270 38 0 0 zabbix_agentd
[38617319.591991] [14803] 5000 14803 20750 255 38 0 0 zabbix_agentd
[38617319.591993] [14805] 5000 14805 20750 255 38 0 0 zabbix_agentd
[38617319.591994] Out of memory: Kill process 14164 (java) score 258 or sacrifice child
[38617319.594257] Killed process 14164 (java) total-vm:8128852kB, anon-rss:4192624kB, file-rss:148kB, shmem-rss:0kB
|
1
2
3
4
5
6
7
8
9
10
11
12
| [webapp@hd2-cil-rs-app-01 ~]$ sudo vim /var/log/messages
.
.
.
Apr 21 21:36:40 hd2-cil-rs-app-01 kernel: [13608] 10006 13608 28879 143 14 0 0 bash
Apr 21 21:36:40 hd2-cil-rs-app-01 kernel: [14164] 10006 14164 2032213 1048193 2198 0 0 java
Apr 21 21:36:40 hd2-cil-rs-app-01 kernel: [14784] 10006 14784 30864 447 18 0 0 htop
Apr 21 21:36:40 hd2-cil-rs-app-01 kernel: [14802] 5000 14802 20750 270 38 0 0 zabbix_agentd
Apr 21 21:36:40 hd2-cil-rs-app-01 kernel: [14803] 5000 14803 20750 255 38 0 0 zabbix_agentd
Apr 21 21:36:40 hd2-cil-rs-app-01 kernel: [14805] 5000 14805 20750 255 38 0 0 zabbix_agentd
Apr 21 21:36:40 hd2-cil-rs-app-01 kernel: Out of memory: Kill process 14164 (java) score 258 or sacrifice child
Apr 21 21:36:40 hd2-cil-rs-app-01 kernel: Killed process 14164 (java) total-vm:8128852kB, anon-rss:4192624kB, file-rss:148kB, shmem-rss:0kB
|
立即重启应用,并给springboot应用加上内存限制参数,如下,最大允许内存2G,并在OOM时保存内存快照,以及打印GC日志。
1
2
3
4
5
6
7
8
9
10
11
12
13
| java -jar
-server
-Xms1024M
-Xmx2048M
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/opt/neu-marketing-service/current/dump
-XX:+UseGCLogFileRotation
-XX:+PrintGCDateStamps
-Xloggc:/opt/neu-marketing-service/current/gc-%t.log
-XX:+PrintGC
-XX:+UseConcMarkSweepGC
-Dspring.profiles.active=product
neu-marketing.jar
|
CPU满载
应用重启后,刚开始几分钟很正常,但是很快监控报警CPU占用过高,并且应用很快不再响应外部的任何请求,所有的HTTP请求全部阻塞直到网关超时。
通过top以及htop命令立即定位到CPU占用高的进程正是刚刚重启的应用。然后通过如下命令,来定位java应用是那个线程占用CPU过高:
1
2
3
| [webapp@hd2-cil-rs-app-01 current]$ ps -aux | grep marketing
webapp 24161 2.0 11.9 8257484 1941828 ? Sl 4月21 21:41 java -jar -server -Xms1024M -Xmx2048M -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/opt/neu-marketing-service/current/dump -Dspring.profiles.active=product -XX:+UseGCLogFileRotation -XX:+PrintGCDateStamps -Xloggc:/opt/neu-marketing-service/current/gc-%t.log -XX:+PrintGC -XX:+UseConcMarkSweepGC neu-marketing.jar
webapp 29709 0.0 0.0 112680 964 pts/4 S+ 10:02 0:00 grep marketing
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| [webapp@hd2-cil-rs-app-01 current]$ ps -mp 24161 -o THREAD,tid,time
USER %CPU PRI SCNT WCHAN USER SYSTEM TID TIME
webapp 200 - - - - - - 00:06:08
webapp 0.0 19 - futex_ - - 24161 00:00:00
webapp 25.3 19 - futex_ - - 24163 00:00:46
webapp 0.8 19 - futex_ - - 24164 00:00:01
webapp 0.9 19 - futex_ - - 24165 00:00:01
webapp 0.8 19 - futex_ - - 24166 00:00:01
webapp 0.9 19 - futex_ - - 24167 00:00:01
webapp 1.9 19 - futex_ - - 24168 00:00:03
webapp 0.7 19 - futex_ - - 24169 00:00:01
webapp 0.0 19 - futex_ - - 24170 00:00:00
webapp 0.0 19 - futex_ - - 24171 00:00:00
webapp 0.0 19 - futex_ - - 24172 00:00:00
webapp 0.0 19 - futex_ - - 24173 00:00:00
webapp 31.7 19 - futex_ - - 24174 00:00:58
webapp 31.4 19 - futex_ - - 24175 00:00:57
.
.
.
|
发现tid为24174的线程,CPU占用很高,将该tid转为16进制,并通过jstack命令定位该线程。
1
2
| [webapp@hd2-cil-rs-app-01 current]$ printf "%x" 24174
5e6e
|
1
2
| [webapp@hd2-cil-rs-app-01 current]$ jstack 24161 | grep 5e6e
"C2 CompilerThread0" #6 daemon prio=9 os_prio=0 tid=0x00007f35ec1c8800 nid=0x5e6e waiting on condition [0x0000000000000000]
|
根据输出显示,CPU占用高的并不是用户线程,而是JVM的线程,怀疑是不是GC出了问题。
Full GC
接着排查应用的GC日志,一查直接吓一跳,日志显示应用刚启动时GC很正常,但是几分钟后,频繁出现Full GC甚至一个版面全是Full GC。内存泄漏或者内存不足石锤了,接下来定位具体的内存泄漏位置就令人头疼了。好在这时候应用再次发生OOM,并生成了内存快照,可以用来定位内存泄漏位置。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| 2020-04-21T21:50:54.730+0800: 1.071: [GC (Allocation Failure) 272640K->4882K(1014528K), 0.0092116 secs]
2020-04-21T21:50:55.188+0800: 1.529: [GC (Allocation Failure) 277522K->8403K(1014528K), 0.0121875 secs]
2020-04-21T21:50:55.552+0800: 1.893: [GC (Allocation Failure) 281043K->10651K(1014528K), 0.0108046 secs]
2020-04-21T21:50:55.865+0800: 2.205: [GC (Allocation Failure) 283291K->13062K(1014528K), 0.0119422 secs]
2020-04-21T21:50:55.879+0800: 2.219: [GC (CMS Initial Mark) 18840K(1014528K), 0.0033580 secs]
2020-04-21T21:50:56.475+0800: 2.816: [GC (CMS Final Remark) 247008K(1014528K), 0.0654906 secs]
2020-04-21T21:50:56.655+0800: 2.995: [GC (Allocation Failure) 285702K->11043K(1014528K), 0.0194478 secs]
2020-04-21T21:50:57.463+0800: 3.803: [GC (Allocation Failure) 283683K->22156K(1014528K), 0.0323949 secs]
2020-04-21T21:50:58.064+0800: 4.405: [GC (Allocation Failure) 294796K->28169K(1014528K), 0.0787791 secs]
2020-04-21T21:50:58.579+0800: 4.920: [GC (Allocation Failure) 300809K->27735K(1014528K), 0.0642011 secs]
2020-04-21T21:50:59.367+0800: 5.708: [GC (Allocation Failure) 300375K->30433K(1014528K), 0.0398394 secs]
2020-04-21T21:50:59.856+0800: 6.197: [GC (Allocation Failure) 303073K->32503K(1014528K), 0.0655292 secs]
.
.
.
2020-04-21T21:54:40.923+0800: 227.263: [Full GC (Allocation Failure) 2063100K->2062655K(2063104K), 1.2139026 secs]
2020-04-21T21:54:42.156+0800: 228.496: [Full GC (Allocation Failure) 2063102K->2062830K(2063104K), 0.8924460 secs]
2020-04-21T21:54:43.057+0800: 229.398: [Full GC (Allocation Failure) 2063099K->2062934K(2063104K), 1.1843272 secs]
2020-04-21T21:54:44.251+0800: 230.592: [Full GC (Allocation Failure) 2063101K->2063000K(2063104K), 0.8979688 secs]
2020-04-21T21:54:45.158+0800: 231.499: [Full GC (Allocation Failure) 2063103K->2063038K(2063104K), 1.1687725 secs]
2020-04-21T21:54:46.339+0800: 232.679: [Full GC (Allocation Failure) 2063103K->2063068K(2063104K), 1.1665188 secs]
2020-04-21T21:54:47.514+0800: 233.855: [Full GC (Allocation Failure) 2063096K->2063088K(2063104K), 1.1507210 secs]
2020-04-21T21:54:48.673+0800: 235.014: [Full GC (Allocation Failure) 2063103K->2063096K(2063104K), 1.2230892 secs]
2020-04-21T21:54:49.902+0800: 236.243: [GC (CMS Initial Mark) 2063102K(2063104K), 0.0594648 secs]
2020-04-21T21:54:50.294+0800: 236.634: [Full GC (Allocation Failure) 2063103K->2063096K(2063104K), 0.8812470 secs]
2020-04-21T21:54:51.183+0800: 237.524: [Full GC (Allocation Failure) 2063096K->2063096K(2063104K), 0.8718934 secs]
2020-04-21T21:54:52.063+0800: 238.404: [Full GC (Allocation Failure) 2063096K->2063004K(2063104K), 1.2422705 secs]
|
Dump文件分析
下载内存快照到本地分析,内存快照文件非常大达到2.2G,建议压缩后再下载,如下,这次的2.2G大小的内存快照压缩后仅剩95M大小,直接压缩成了原来大小的4%。
1
2
3
4
| [webapp@hd2-cil-rs-app-01 current]$ ls -hl
总用量 2.2G
-rw------- 1 webapp webapp 2.1G 4月 21 21:55 dump
-rw-rw-r-- 1 webapp webapp 95M 4月 22 16:48 dump.zip
|
分析内存快照推荐使用MAT,是eclipse官方推出的本地内存分析工具,下载链接是https://www.eclipse.org/mat/downloads.php。
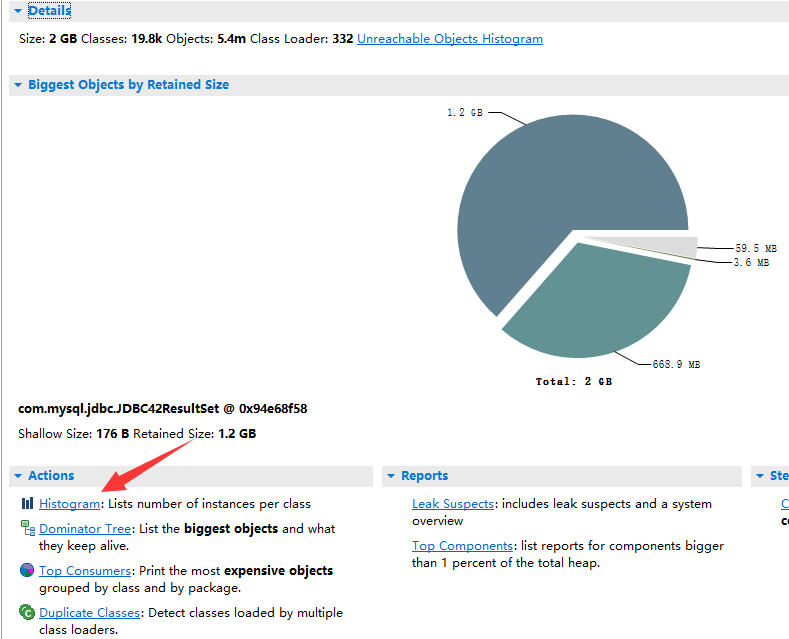
MAT解析内存快照结果如下图,立即分析出来com.mysql.jdbc.JDBC42ResultSet的对象占用了1.2G的内存,从类名可以分析出来这次OOM的罪魁祸首是一次mysql的数据库查询,由于查询结果太多导致内存不足而频繁Full GC乃至最终OOM了。
Leak Suspects
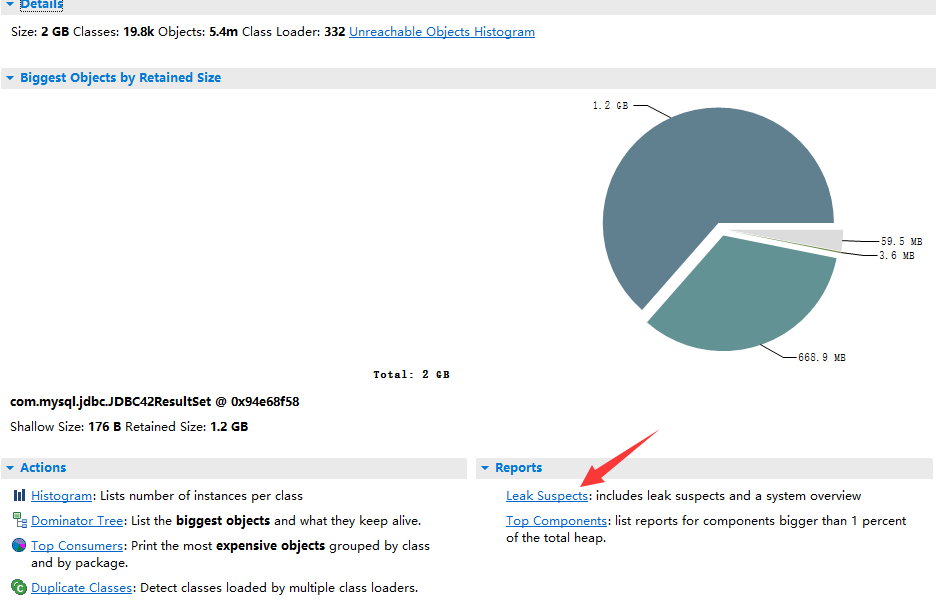
通过Leak Suspects,快速分析快照文件,MAT提示有如下两个内存问题:
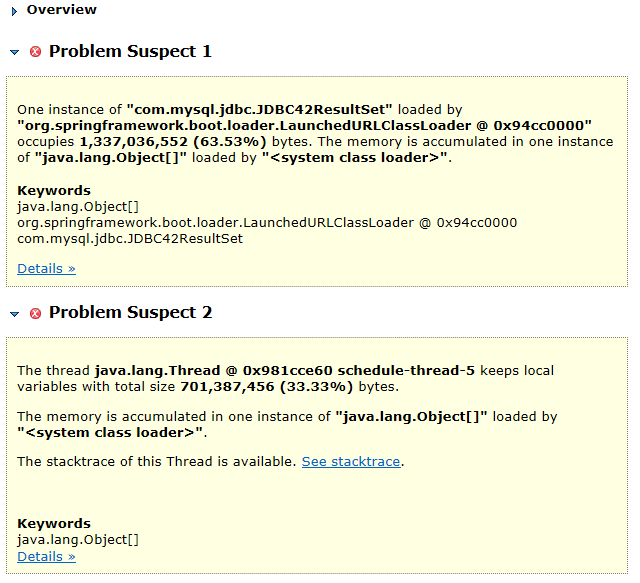
点击第一个问题的Details按钮,发现泄漏的内存引用的对象中,有一个是用户自己创建的定时任务线程,继续查看该线程对象的引用关系,成功定位到发生OOM的方法位置。
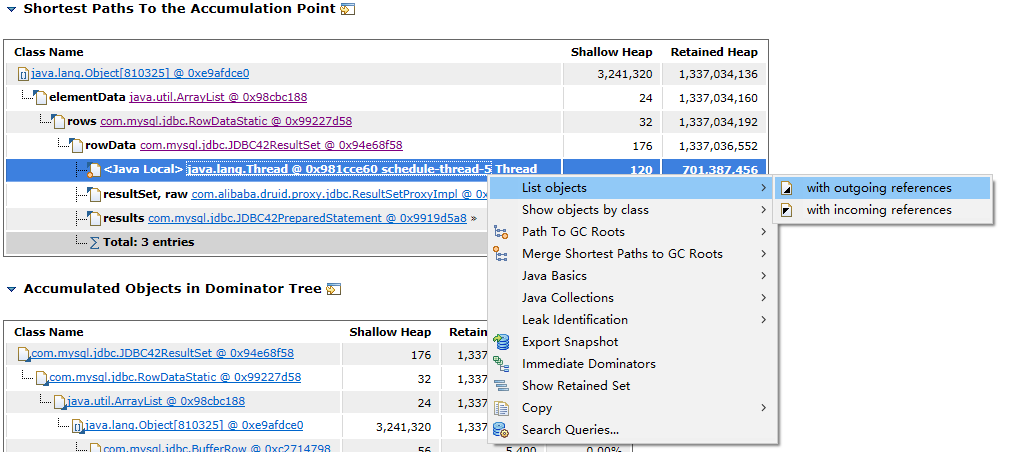
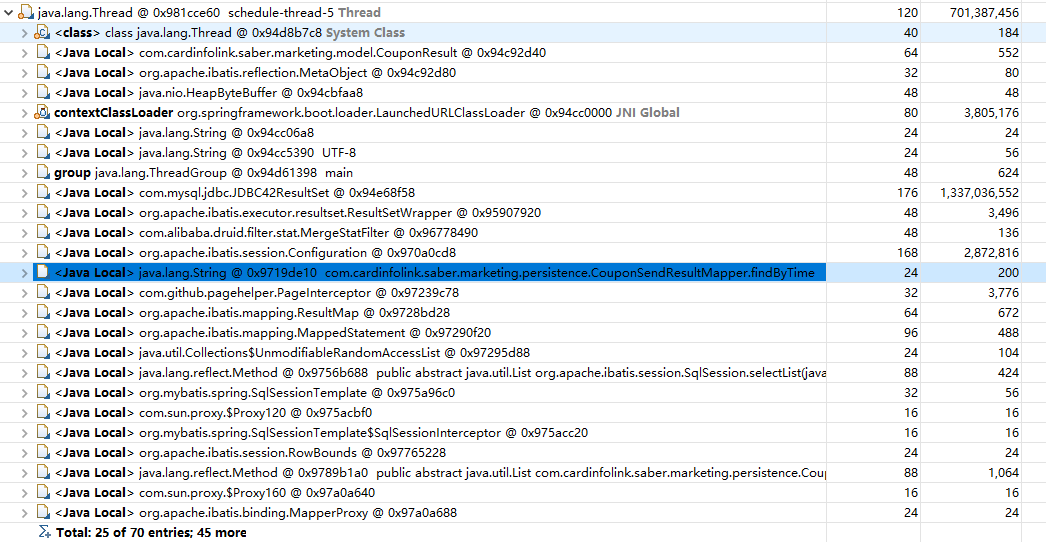
再查看第二个问题,第二个问题直接提供了OOM时的异常栈查看,查看异常栈,轻松定位到OOM的位置。
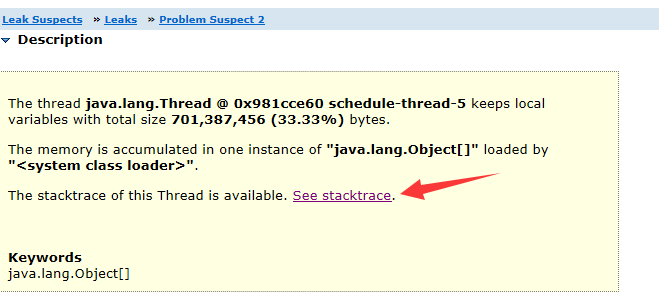

最后发现两个问题实际上都指向了同一个位置,即发生OOM的罪魁祸首。这时候就需要对这一处代码进行code review了,从代码层面排查OOM的原因。
Histogram
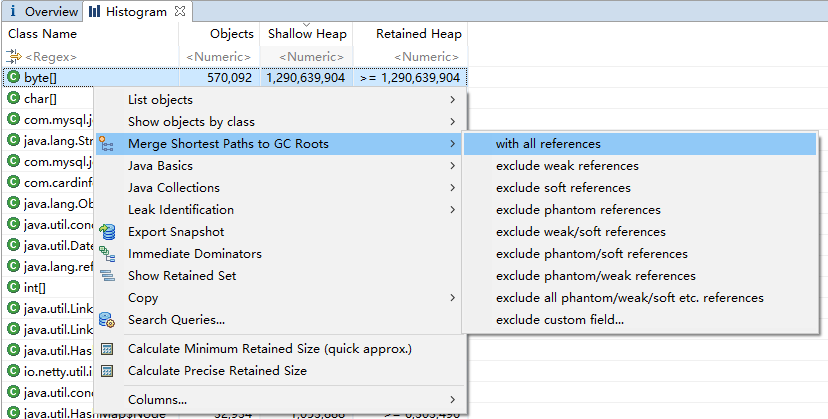
同样也可以通过内存排行Histogram来定位OOM位置,如下图
通过内存排行可见,byte[]占用了1.2G的内存,查看该对象的引用对象内存排行
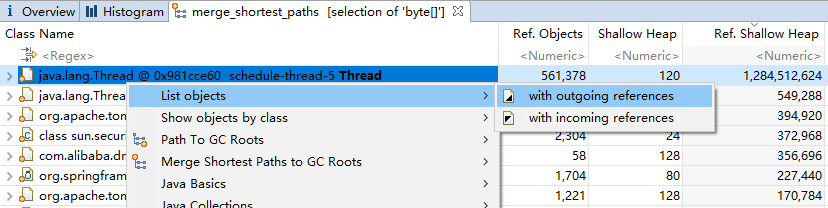
可见byte[]的引用对象中,用户线程schedule-thread-5占用的内存最高,接着查看该对象的引用关系,同样可以定位到内存泄漏的具体位置。
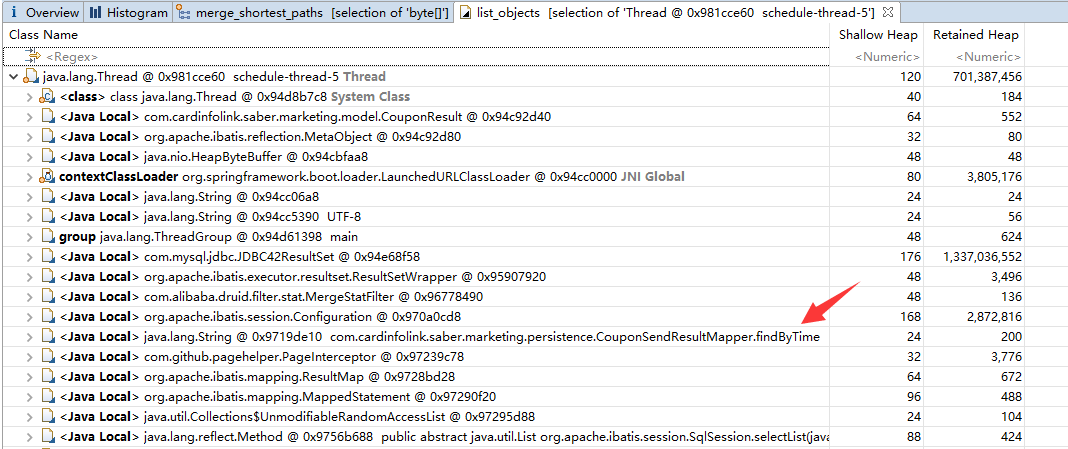
问题定位
根据MAT定位出来的位置进行code review代码后,发现定时任务定时触发该代码,逻辑为从mysql中查询待处理的记录,但是却没有加上单次查询的数量限制。平时数据量不大,因此这个问题并没有引起任何明显的现象,但是这次涉及600W数据的操作,导致该逻辑需要查询的记录数量直接增长到了百万级别。
结果定时任务一次性从mysql查询读取数百万条记录,应用内存迅速耗尽而触发频繁的Full GC。由于频繁的Full GC,导致应用假死、所有请求阻塞直到网关超时,最终内存不足发生OOM异常。
解决
问题定位分析完毕后,解决就非常简单了,直接给该查询添加上单次查询上限,加个limit限制就解决了这次的OOM问题。
代码迅速上线后,应用立即恢复正常,监控也不再提示任何警告。