kueue执行源码分析
1. kueue
1.1 概念
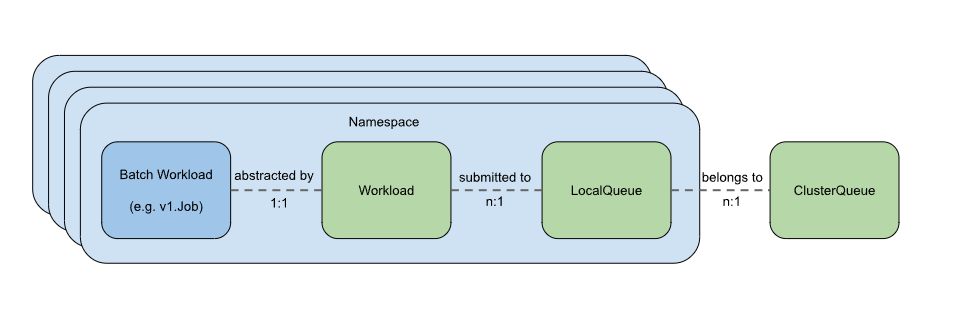
1.2 样例
1 | apiVersion: v1 |
将多个Pod提交到kueue的队列中,如下图所示,队列资源不足时,Pod的状态阻塞并标记为SchedulingGated。
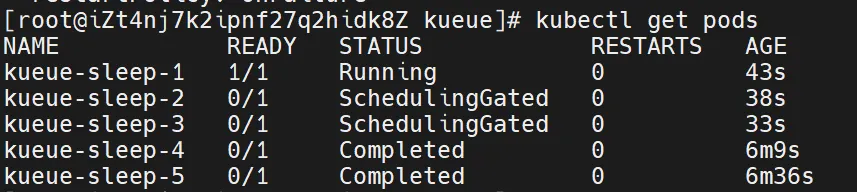
查看被kueue阻塞的Pod信息,如下:
1 | apiVersion: v1 |
2. schedulingGates
2.1. k8s特性
Kueue是如何实现阻塞Pod的调度创建?K8s在1.27版本添加特性支持schedulingGates,如果Pod中spec的schedulingGates不为空时,则K8s不会调度该Pod的执行,直到该Pod中spec的schedulingGates被移除后,K8s才会继续调度创建该Pod。
该特性文档见以下文档:
- https://github.com/orgs/kubernetes/projects/117/views/1?filterQuery=3521&pane=issue&itemId=17721636
- https://github.com/kubernetes/enhancements/blob/master/keps/sig-scheduling/3521-pod-scheduling-readiness/README.md
2.2. 实践
如下yaml文件添加的spec.schedulingGates值,提交后如下图,在资源足够的情况下,Pod的状态依然阻塞并标记为SchedulingGated。
1 | apiVersion: v1 |

移除spec.schedulingGates的值,重新提交后如下图,该Pod被K8s正常调度创建,状态推进到Running。

3. 整体流程
梳理kueue的源代码后,核心主链路流程如下:
- 用户提交Pod,K8s创建Pod,状态为Pending
- kueue的pod_webhook监听到Pod的创建事件,添加Pod中spec的schedulingGates值,通过K8s的特性阻塞该Pod的创建调度
- kueue的reconciler监听到事件,发现该Pod需要被kueue接管,但是没有对应的workload,自动创建关联一个workload
- kueue的workload_controller监听到workload的创建事件,将该workload实例push到所属的ClusterQueue中
- kueue的scheduler轮询ClusterQueue,按优先级和资源额度从队列Pop出待执行的workload,修改状态为已提交
- kueue的reconciler监听事件,发现Pod关联的workload状态已提交,则移除Pod中spec的schedulingGates值,不再阻塞该Pod的创建调度,Pod正常创建执行
- Pod执行完成/失败
- kueue的reconciler监听事件,发现Pod已经完成/失败,修改关联的workload状态为终态
- kueued的workload_controller监听workload的状态更新,并同时更新关联的ClusterQueue的资源使用状态
4. 源码分析
4.1. 阻塞Pod创建调度
pkg\controller\jobs\pod\pod_webhook.go
1 | // 监听k8s的Pod创建 |
4.2. Pod自动关联创建workload
pkg\controller\jobframework\reconciler.go
1 |
|
4.3. workload关联到所属队列
pkg\controller\core\workload_controller.go
1 | // 监听workload的创建事件 |
pkg\queue\manager.go
1 | // AddOrUpdateWorkload adds or updates workload to the corresponding queue. |
pkg\queue\cluster_queue.go
1 | // PushOrUpdate pushes the workload to ClusterQueue. |
4.4. 队列执行workload
pkg\scheduler\scheduler.go
1 | func (s *Scheduler) schedule(ctx context.Context) wait.SpeedSignal { |
4.5. Pod取消阻塞
pkg\controller\jobframework\reconciler.go
1 |
|
pkg\controller\jobframework\reconciler.go
1 | func (r *JobReconciler) startJob(ctx context.Context, job GenericJob, object client.Object, wl *kueue.Workload) error { |
pkg\controller\jobs\pod\pod_controller.go
1 |
|
4.6. workload状态推进到终态
pkg\controller\jobframework\reconciler.go
1 |
|
4.7. 队列资源状态自动更新
pkg\controller\core\workload_controller.go
1 | // 监听workload的更新事件 |
pkg\cache\cache.go
1 | func (c *Cache) UpdateWorkload(oldWl, newWl *kueue.Workload) error { |
pkg\cache\clusterqueue.go
1 | func (c *clusterQueue) addWorkload(w *kueue.Workload) error { |