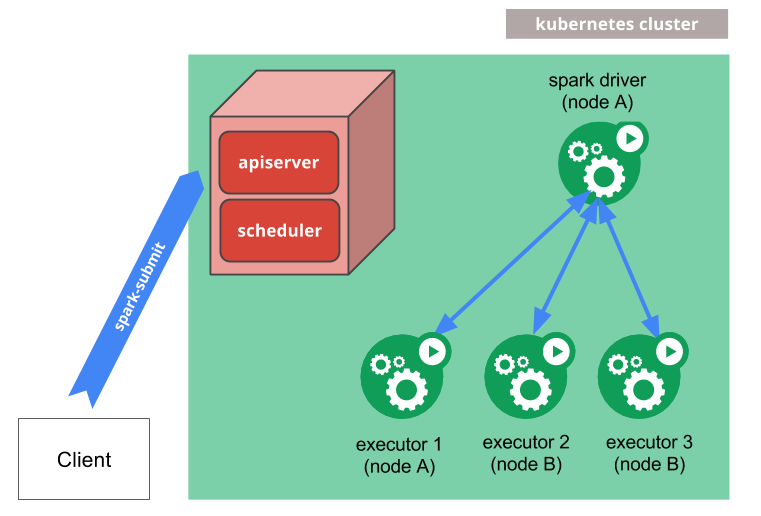
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
|
override def createSchedulerBackend(
sc: SparkContext,
masterURL: String,
scheduler: TaskScheduler): SchedulerBackend = {
...
val kubernetesClient = SparkKubernetesClientFactory.createKubernetesClient(
apiServerUri,
Some(sc.conf.get(KUBERNETES_NAMESPACE)),
authConfPrefix,
SparkKubernetesClientFactory.ClientType.Driver,
sc.conf,
defaultServiceAccountCaCrt)
...
val executorPodsAllocator = makeExecutorPodsAllocator(sc, kubernetesClient, snapshotsStore)
val podsWatchEventSource = new ExecutorPodsWatchSnapshotSource(
snapshotsStore,
kubernetesClient,
sc.conf)
val eventsPollingExecutor = ThreadUtils.newDaemonSingleThreadScheduledExecutor(
"kubernetes-executor-pod-polling-sync")
val podsPollingEventSource = new ExecutorPodsPollingSnapshotSource(
sc.conf, kubernetesClient, snapshotsStore, eventsPollingExecutor)
new KubernetesClusterSchedulerBackend(
scheduler.asInstanceOf[TaskSchedulerImpl],
sc,
kubernetesClient,
schedulerExecutorService,
snapshotsStore,
executorPodsAllocator,
executorPodsLifecycleEventHandler,
podsWatchEventSource,
podsPollingEventSource)
}
private[k8s] def makeExecutorPodsAllocator(sc: SparkContext, kubernetesClient: KubernetesClient,
snapshotsStore: ExecutorPodsSnapshotsStore) = {
...
cstr.newInstance(
sc.conf,
sc.env.securityManager,
new KubernetesExecutorBuilder(),
kubernetesClient,
snapshotsStore,
new SystemClock())
}
|