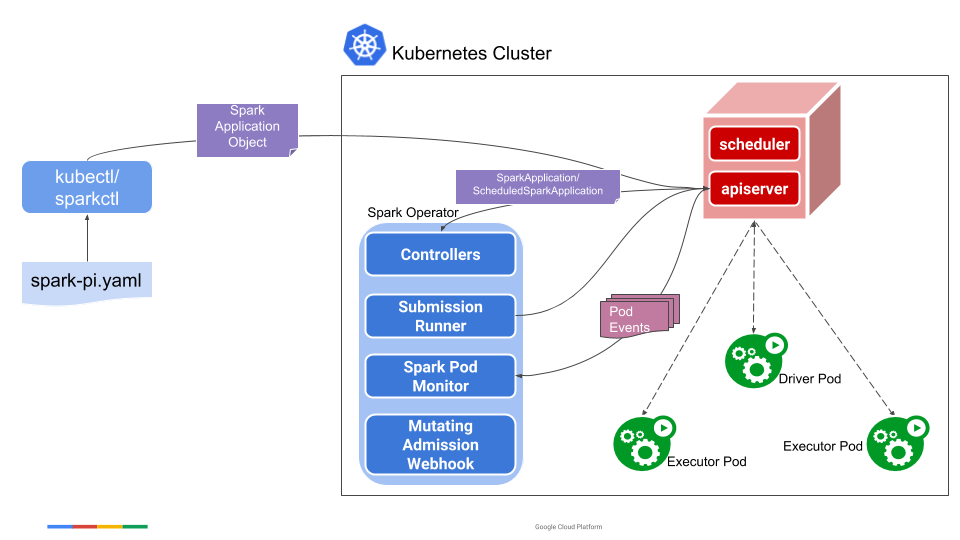
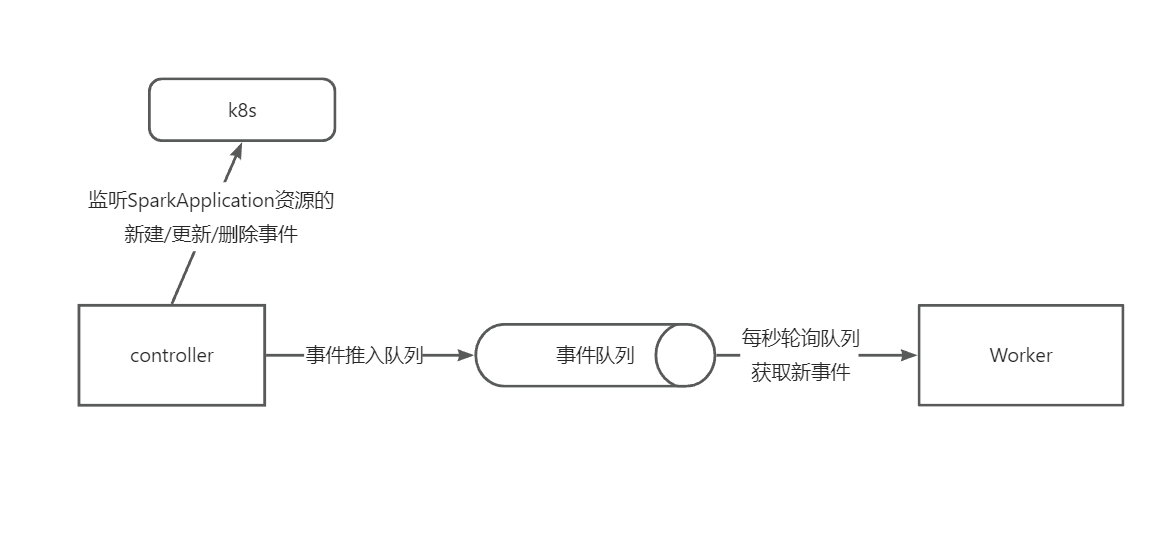
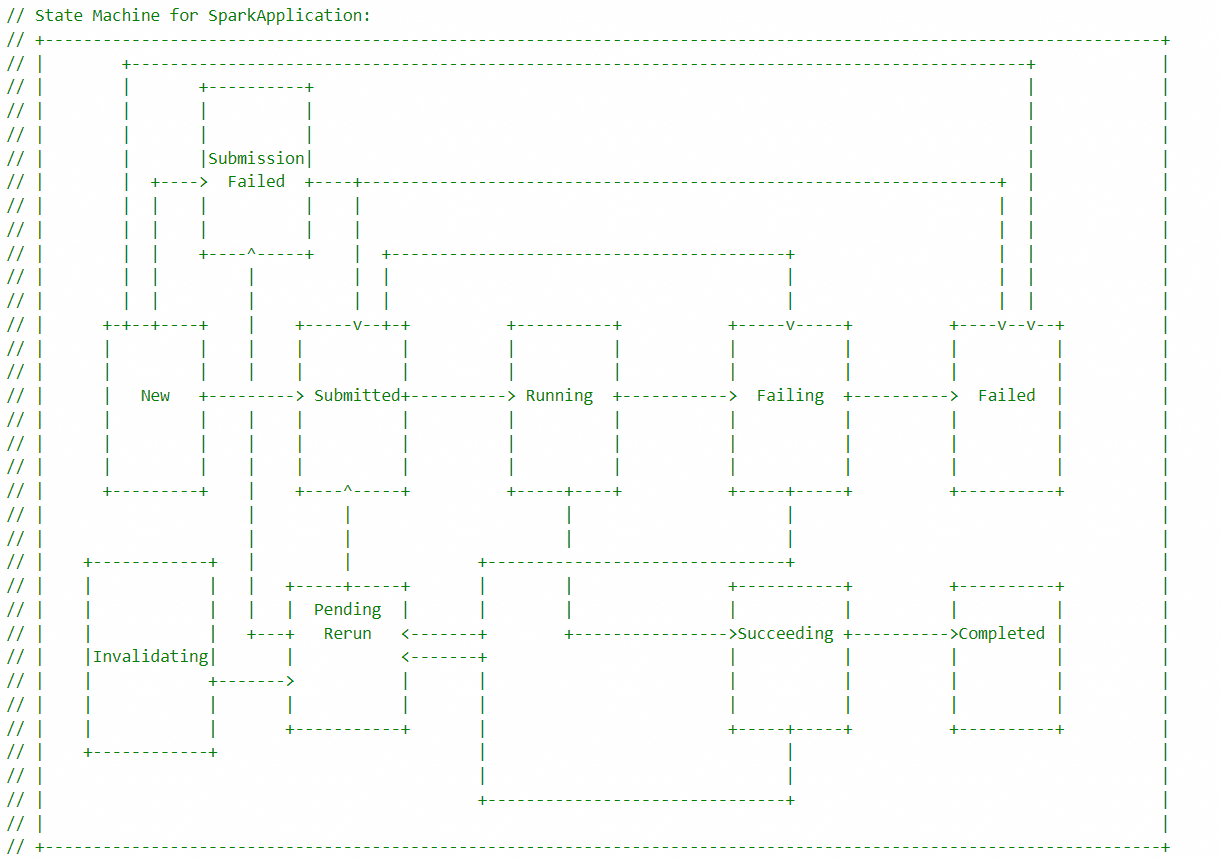
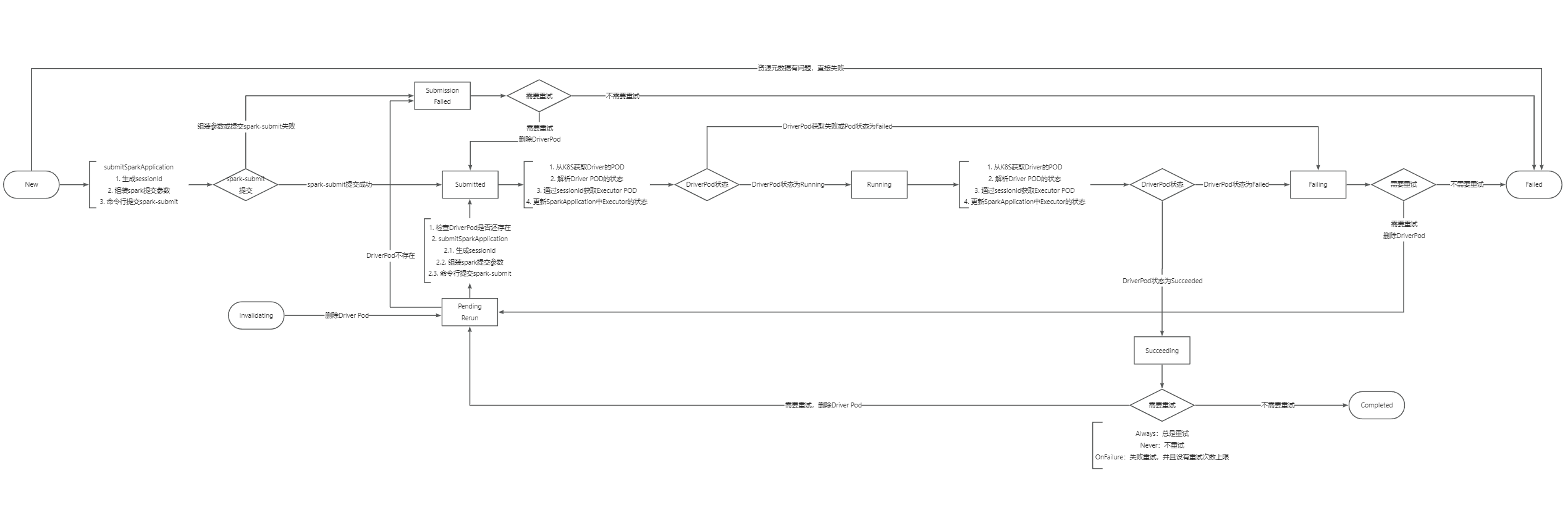
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
|
func (c *Controller) syncSparkApplication(key string) error {
namespace, name, err := cache.SplitMetaNamespaceKey(key)
if err != nil {
return fmt.Errorf("failed to get the namespace and name from key %s: %v", key, err)
}
app, err := c.getSparkApplication(namespace, name)
if err != nil {
return err
}
if app == nil {
return nil
}
if !app.DeletionTimestamp.IsZero() {
c.handleSparkApplicationDeletion(app)
return nil
}
appCopy := app.DeepCopy()
v1beta2.SetSparkApplicationDefaults(appCopy)
switch appCopy.Status.AppState.State {
case v1beta2.NewState:
c.recordSparkApplicationEvent(appCopy)
if err := c.validateSparkApplication(appCopy); err != nil {
appCopy.Status.AppState.State = v1beta2.FailedState
appCopy.Status.AppState.ErrorMessage = err.Error()
} else {
appCopy = c.submitSparkApplication(appCopy)
}
case v1beta2.SucceedingState:
if !shouldRetry(appCopy) {
appCopy.Status.AppState.State = v1beta2.CompletedState
c.recordSparkApplicationEvent(appCopy)
} else {
if err := c.deleteSparkResources(appCopy); err != nil {
glog.Errorf("failed to delete resources associated with SparkApplication %s/%s: %v",
appCopy.Namespace, appCopy.Name, err)
return err
}
appCopy.Status.AppState.State = v1beta2.PendingRerunState
}
case v1beta2.FailingState:
if !shouldRetry(appCopy) {
appCopy.Status.AppState.State = v1beta2.FailedState
c.recordSparkApplicationEvent(appCopy)
} else if isNextRetryDue(appCopy.Spec.RestartPolicy.OnFailureRetryInterval, appCopy.Status.ExecutionAttempts, appCopy.Status.TerminationTime) {
if err := c.deleteSparkResources(appCopy); err != nil {
glog.Errorf("failed to delete resources associated with SparkApplication %s/%s: %v",
appCopy.Namespace, appCopy.Name, err)
return err
}
appCopy.Status.AppState.State = v1beta2.PendingRerunState
}
case v1beta2.FailedSubmissionState:
if !shouldRetry(appCopy) {
appCopy.Status.AppState.State = v1beta2.FailedState
c.recordSparkApplicationEvent(appCopy)
} else if isNextRetryDue(appCopy.Spec.RestartPolicy.OnSubmissionFailureRetryInterval, appCopy.Status.SubmissionAttempts, appCopy.Status.LastSubmissionAttemptTime) {
if c.validateSparkResourceDeletion(appCopy) {
c.submitSparkApplication(appCopy)
} else {
if err := c.deleteSparkResources(appCopy); err != nil {
glog.Errorf("failed to delete resources associated with SparkApplication %s/%s: %v",
appCopy.Namespace, appCopy.Name, err)
return err
}
}
}
case v1beta2.InvalidatingState:
if err := c.deleteSparkResources(appCopy); err != nil {
glog.Errorf("failed to delete resources associated with SparkApplication %s/%s: %v",
appCopy.Namespace, appCopy.Name, err)
return err
}
c.clearStatus(&appCopy.Status)
appCopy.Status.AppState.State = v1beta2.PendingRerunState
case v1beta2.PendingRerunState:
glog.V(2).Infof("SparkApplication %s/%s is pending rerun", appCopy.Namespace, appCopy.Name)
if c.validateSparkResourceDeletion(appCopy) {
glog.V(2).Infof("Resources for SparkApplication %s/%s successfully deleted", appCopy.Namespace, appCopy.Name)
c.recordSparkApplicationEvent(appCopy)
c.clearStatus(&appCopy.Status)
appCopy = c.submitSparkApplication(appCopy)
}
case v1beta2.SubmittedState, v1beta2.RunningState, v1beta2.UnknownState:
if err := c.getAndUpdateAppState(appCopy); err != nil {
return err
}
case v1beta2.CompletedState, v1beta2.FailedState:
if c.hasApplicationExpired(app) {
glog.Infof("Garbage collecting expired SparkApplication %s/%s", app.Namespace, app.Name)
err := c.crdClient.SparkoperatorV1beta2().SparkApplications(app.Namespace).Delete(context.TODO(), app.Name, metav1.DeleteOptions{GracePeriodSeconds: int64ptr(0)})
if err != nil && !errors.IsNotFound(err) {
return err
}
return nil
}
if err := c.getAndUpdateExecutorState(appCopy); err != nil {
return err
}
}
if appCopy != nil {
err = c.updateStatusAndExportMetrics(app, appCopy)
if err != nil {
glog.Errorf("failed to update SparkApplication %s/%s: %v", app.Namespace, app.Name, err)
return err
}
if state := appCopy.Status.AppState.State; state == v1beta2.CompletedState ||
state == v1beta2.FailedState {
if err := c.cleanUpOnTermination(app, appCopy); err != nil {
glog.Errorf("failed to clean up resources for SparkApplication %s/%s: %v", app.Namespace, app.Name, err)
return err
}
}
}
return nil
}
|