系统优化复盘一二三
背景
2020年下半年的某个周五下午,作为主开发的我请假出去摸鱼了,然后下午四点左右突然的服务器报警不约而至,各个应用大量报错显示网络超时。人在外,只能拜托其他同事帮忙排查问题了,同事排查后发现是Nginx服务器的CPU满载导致的服务不可用,并于半小时后恢复正常。
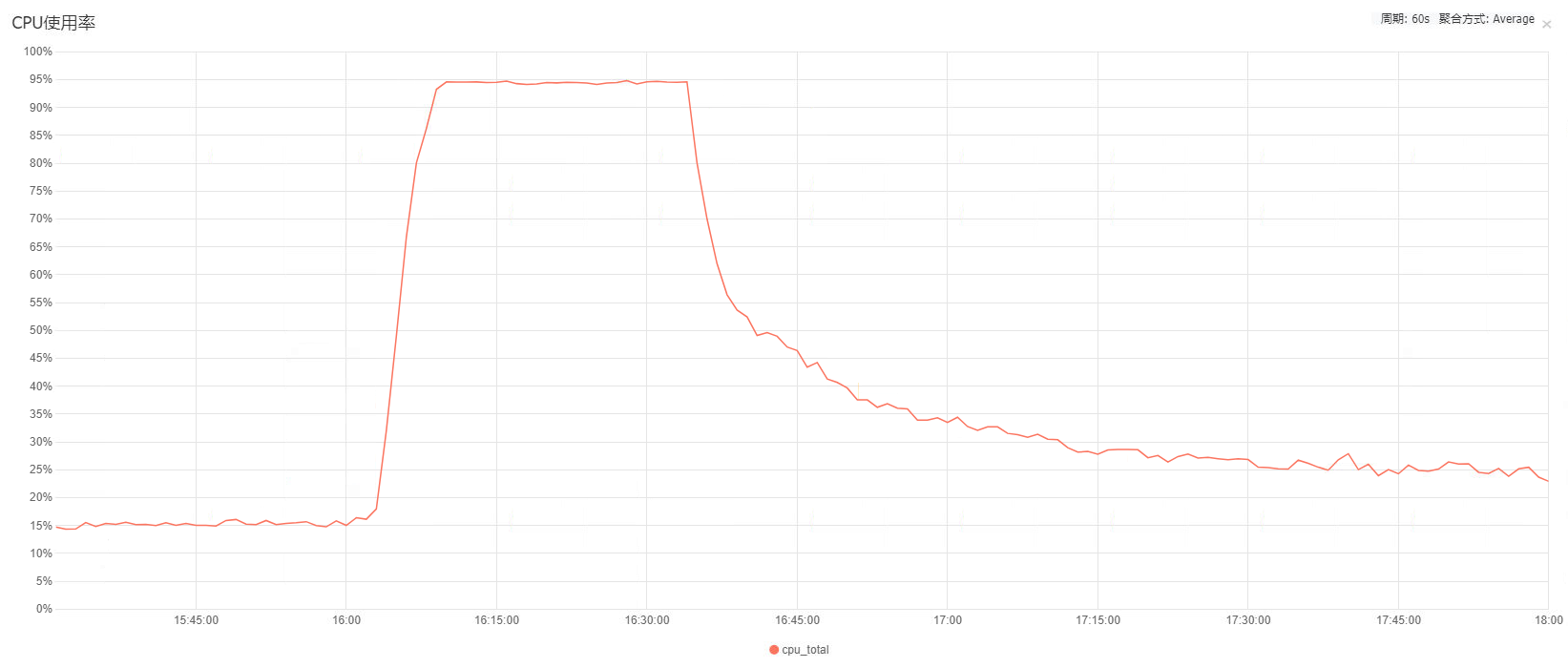
回到公司后自己排查发现,确实是Nginx服务器故障了,故障期间Nginx服务器的带宽几乎打满,CPU长达半小时的时间内100%荷载。为了进一步分析问题原因,就把故障期间的Nginx日志扒下来解析分析统计,发现是大量的前端请求营销活动的H5页面,下载静态资源文件占用了故障期间的90%以上的带宽。至于为什么各个后端应用也报错网络超时,则是我们项目架构不合理的原因。如下图,如果前端请求A应用,A应用再请求B应用,其网络调用链路应该如下图。
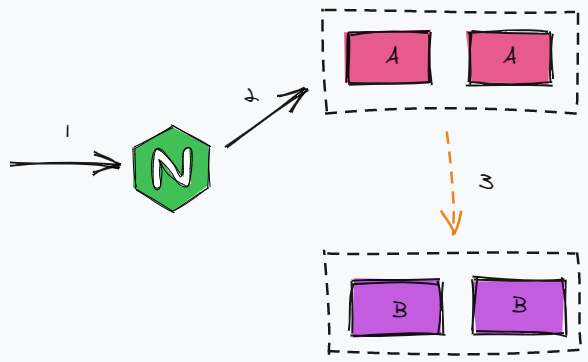
但实际上我们项目的架构如下图,因为没有引入注册中心,所以后端应用之间的调用是通过Nginx做负载均衡,且该Nginx与前端Nginx为同一个Nginx。这也就导致了当前端的静态资源流量把Nginx服务器打满后,后端应用之间的网络服务调用也受到了影响,从而大面积报错服务调用网络超时。
初步分析
后来通过同事了解到,有个大商户通过微信公众号推送了我们项目的营销活动H5领券页面,再加上该商户拥有2000万的公众号粉丝和1600万的注册会员,所以导致H5资源访问打垮了Nginx服务器。
问题似乎一下清晰了,把Nginx的访问日志以及分析结果绘成的流量占用图扔给了项目组长以及前端同事,然后就由前端同事接走了锅负责问题的修复。
解决方案也非常简单,就是把前端的所有静态资源文件全部上传到CDN,Nginx服务器尽可能不处理静态资源的访问。
第二次事故
第一次事故发生后的第二个月,引发该事故的商户提前跟我们组打招呼说下午4点再来一次营销推送,还跟上次一样通过微信公众号给2000万粉丝推送营销活动H5领券页面。这次我们拍着胸脯说肯定没问题,已经做了对应的优化了,然后就被啪啪打脸了。
下午4点商户准时推送了微信公众号,然后我们眼睁睁地看着Nginx服务器的CPU荷载100%打满。Nginx服务器坚持的时长比第一次久一些,但最终还是带宽打满CPU满载,并和上次一样后端应用之间的服务调用大面积报错网络超时。
连续两次营销活动推送故障并影响到了其他的正常主业务,多个商户表示不满,我们项目组则暂缓手头目前的需求任务,把系统优化作为接下来一个月的主要工作。
再次分析
再一次扒Nginx日志解析分析统计,发现这次的Nginx流量占比中静态资源占小部分,绝大部分都是后端服务之间调用占用的。主要分析如下:
- 上次前端静态资源上传CDN的改造覆盖面不完整,还有部分静态资源遗漏
- 后端服务之间调用返回报文中无用字段过长导致报文臃肿,甚至出现一个返回报文长达几十KB而实际有效字段仅十几个字节
- 后端服务之间的服务调用使用了HTTPS,且部分应用使用的HTTP短连接,导致Nginx处理高频率HTTPS的TLS握手浪费了大量的CPU性能
- 应用对几乎不变的数据没有加缓存,重复调用其他应用服务导致网络IO浪费
初步方案
针对分析结果,这次故障的主要原因就是报文的无用字段太长报文臃肿,以及后端服务之间的网络调用没有使用直连的方式。因此第一步的主要改造点如下:
- 注册中心搭建,后端服务之间的服务发现通过注册中心实现,后端的网络调用不再通过Nginx,各个后端应用之间使用HTTP直连,降低Nginx的负载
- 对臃肿报文进行裁剪,只返回调用方需要的关键字段,从而降低网络IO和各个应用的GC
- 对于几乎不变的服务调用结果做缓存,降低网络IO
- Nginx做限流,营销活动这种容忍失败且优先级低于主业务的场景,针对几个突发流量高的接口做限流处理,避免影响到主业务
- 前端遗漏的静态资源上传到CDN
第二次分析
以上方案匆匆忙忙改造完成后,用测试环境进行了一波压测,虽然测试环境配置远低于生产,但压测数据并不是很理想。压测过程中Nginx服务器的带宽压力和CPU荷载不高,因此改造确实没有问题,但还有额外的优化空间。
进一步优化则需要对后端应用进行分析,常用的方式有On-CPU火焰图分析CPU使用分布、时钟火焰图和链路追踪埋点分析各个线程执行耗时时间的分布等。借助于arthas工具的火焰图事件采集对几个压测系统进行性能分析,得出以下信息:
- 用户每次与营销系统交互,营销系统都通过Cookie向SSO系统查询用户ID,虽然耗时不长,当该流程可以优化
- 营销系统打印了大量的无用日志,压测期间日志打印占用的CPU荷载和耗时较大
- 压测期间营销系统和券系统高频率访问的mysql数据虽然使用了redis缓存,但作为热点数据,访问redis缓存的网络耗时消耗可观
- 券系统发券前对领券活动的用户合计领取/每日领取张数限制逻辑实现不合理
- GC频繁
第二次方案
会话登录优化
大量登录用户请求营销系统时,即使营销系统对用户会话做缓存,但对于营销活动用户抢券这种低频率场景,用户会话缓存的命中率并不高,因此我们从其他方面着手改造。
当前营销系统对于用户会话只需要获取用户ID,其他信息都不必要,因此改造SSO的Cookie生成逻辑,Cookie的值为加密的JSON,其中包含了用户ID和Cookie的过期时间。从而营销系统接收到用户请求后不再需要额外请求SSO系统,直接按预定义的算法从Cookie中解密出用户ID。
日志打印优化
无用日志打印的问题很好解决,挨个排查日志打印的代码,仅打印关键信息日志即可。
热点数据优化
热点数据为活动配置和券配置信息,都是更新频率极低且容忍数据短时间不一致的场景。因此对于这两种热点数据采用堆内缓存+redis缓存的双重缓存方案,具体实现逻辑如下图。
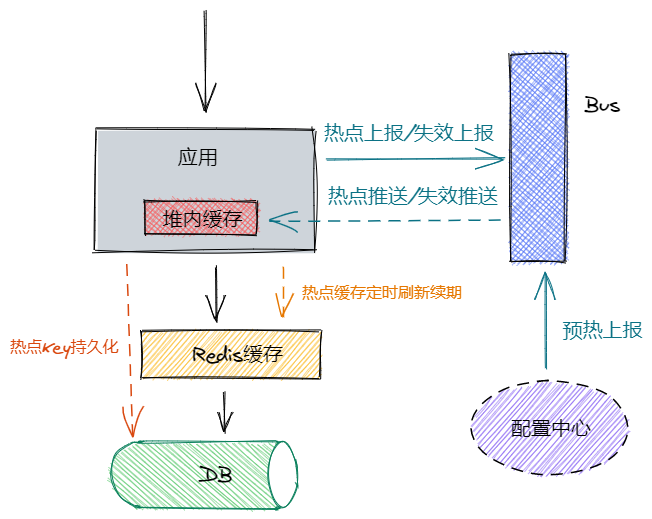
热点发现
暂定QPS超过200的记录就记为热点数据,由于生产环境当前只有4个节点,为了降低热点数据计数消耗,只要一个节点在内存中计数发现活动配置/券配置的某条记录当前节点的每秒访问次数超过50次,则标记该记录为热点数据。
热点上报/失效上报
热点数据信息会通过kafka推送到该服务的所有节点,且同一条记录短时间内最多推送一次,避免不必要的网络IO消耗。默认对于非热点数据只启用redis缓存读写,当应用节点收到热点数据通知后,记录该热点数据ID,对于热点数据启用堆内缓存+redis缓存。
另外为了能够通过人工提前对热点数据预热,我们也实现了通过配置中心将预热的热点数据key推送到集群各个节点,从而实现热点数据的预热。
对于热点数据更新发生的热点失效问题,直接同步更新redis缓存,然后通过kafka上报热点失效,通知该服务的所有节点失效该记录的堆内缓存,保证缓存数据最终一致性。以及为了防止出现缓存击穿的问题,各节点定时刷新和续期热点数据的堆内缓存,另外主节点还额外负责定时刷新和续期热点数据的redis缓存。
热点key持久化
每当有热点上报或失效上报时,主节点额外负责将当前热点key持久化到数据库中,保证应用节点重启后能及时从数据库获取当前的热点key,从而不会出现由于没有命中热点缓存导致缓存击穿的问题。
发券限制实现优化
业务代码优化,原先发券流程中对于用户每日领券数量控制的实现方式是从mysql的用户券码表实时查询用户当日已发券数量,但营销活动短时间爆发大量用户领券的场景下,该方案令mysql的压力较大。
因此优化实现方式,通过redis计数累计用户的每日领券数量,降低mysql的查询压力提高接口的响应速度。
GC优化
压测期间营销系统的GC日志显示yong gc频繁但没出现过full gc,配合JVM堆内存监控发现新生代Eden区使用内存增长很快,而Survivor区使用内存增长浮动很小,另外老生代使用内存几乎没有浮动,说明压测期间有大量的对象创建但存活时长短暂,大多数对象都存活不到Survivor区,且几乎没有对象能够长时间存活而晋升到老生代。
GC时长消耗分两部分:对象扫描、存活对象移动,且前者的消耗很小,因此GC的时长取决于每次垃圾回收后存活的对象数量和大小,垃圾回收后存活的对象越多内存越大则GC耗时越久。对于我们这个绝大多数对象都存活不到Survivor区的场景,只需要简单地调整XX:NewSize或XX:NewRatio参数降低老生代大小增加Eden区大小,就可以在单次GC时长几乎不变的前提下延长GC间隔,从而整体降低GC时长的占比。
另外通过arthas工具的alloc事件采集,对几个压测系统压测过程中的内存分配分析发现,主要的内存分配消耗在日志打印、应用服务HTTP调用和redis网络调用上。以上几个优化实现后GC频率进一步下降,剩余几个内存分配较高的代码逻辑由于时间所限暂时忽略。
分库分表
券系统券码单表膨胀到了20G,因此对券码表以用户维度进行水平拆分,通过开源中间件Sharding-Proxy将券码表进行查分。
但由于Sharding-Proxy对于分布式事务支持不够完善,local本地事务不适用于分库分表场景,2PC分布式事务性能影响较大,柔性事务Sharding-Proxy还不支持,因此对于券码表的操作直接放弃数据库事务,通过业务代码实现补偿机制。
分库分表修改面较大,包括分表后sql的修改优化,包括数据统计逻辑的重构等过程,完全可以新开一个篇幅专门记录其中的问题分析、问题解决的过程,因此此处略过。
网关优化
现状
当前的负载均衡逻辑为Nginx做负载均衡,服务发版时通过动态模板解析实现:Jenkins自动化脚本修改Nginx的upstream文件实现。例如对某服务的a、b两节点发版时具体逻辑如下:
- 先修改Nginx的upstream脚本摘除该服务的a节点,执行
reload命令 - 等待Nginx不再有请求路由到a节点后,正常关闭a节点
- 发布a节点的新版本并启动
- 最后再修改Nginx的upstream脚本重新添加a节点,执行
reload命令 - 接着同样的逻辑操作b节点
问题
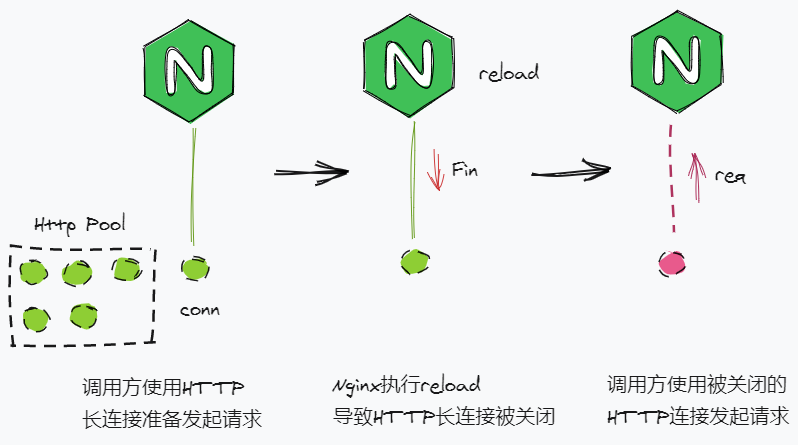
- Nginx执行
reload后会提前主动关闭HTTP长连接,导致调用方对Nginx的请求网络错误,流程如上图 - Nginx的worker进程数量一般配置为CPU核数或CPU核数x2,但
reload会造成一段时间内worker进程数量翻倍,导致进程发生CPU争抢,从而降低了Nginx的性能
方案
Kong网关是基于openresty+lua的开源网关,其提供了内部管理API接口,可以通过这些开放的API接口来管理Kong内部的各个对象,例如上线/下线节点target,详见官方文档admin-api/add-target。通过这种方式修改Nginx的转发逻辑避免了reload命令,不会出现服务端提前主动关闭HTTP长连接以及性能下降的问题。
1 | # 节点上线 |
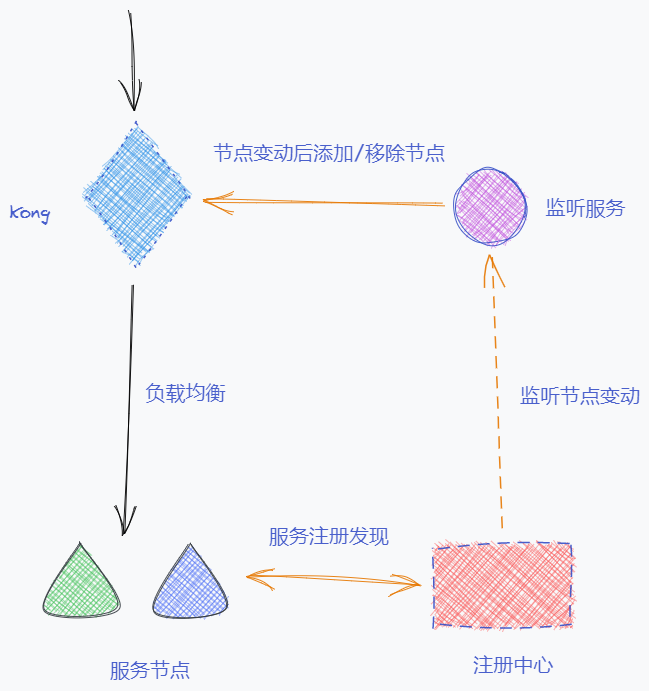
因此可以搭建如上图的架构方案,自行代码实现一个节点监听服务,通过对接注册中心的API来实时监听各个服务节点的状态。当某服务节点上下线后,注册中心将节点上下线事件推送给监听服务,然后监听服务通过Kong的开放API修改该节点对应的Kong中的target对象状态。
通过上述方案从而实现一个注册中心同时管理微服务之间的服务发现和网关到服务的服务发现。此时应用发布流程例如对某服务的a、b两节点发版时具体逻辑如下:
- 请求注册中心下线该服务的a节点
- 监听服务监听到a节点下线后自动将Kong中的a节点下线
- 等待a节点无流量请求后发布重启a节点的新版本
- a节点启动成功后自动将自己重新注册到注册中心
- 监听服务监听到a节点上线后自动将Kong中的a节点上线
- 接着同样的逻辑操作b节点