记一次Nginx服务器CPU满荷载故障
描述
周五请假外出,突然收到监控报警提示Nginx服务器的CPU使用率100%,另外用户也反应服务不可用,同事登录服务器后发现Nginx的进程的CPU使用率100%,且后端应用有大量的服务调用网络超时。
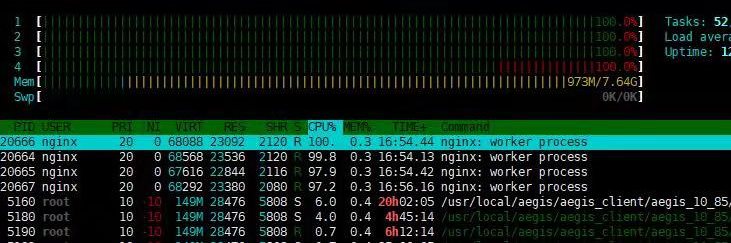
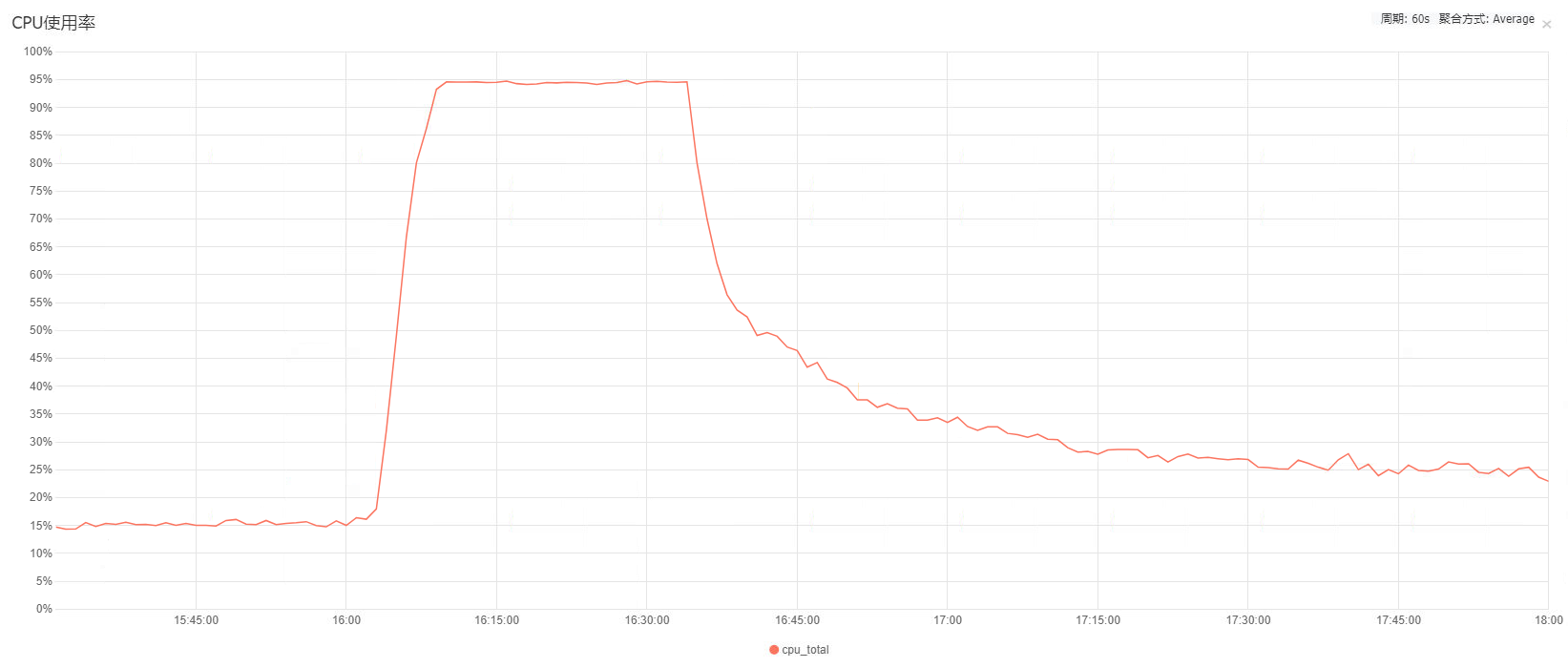
由于Nginx的访问日志并没有被收集到日志分析的Elasticsearch中,所以无法第一时间通过日志分析来统计出访问异常的资源。故障发生半小时后,服务器自动恢复正常,后端应用也不再有网络超时报错了,云服务器的CPU监控和网络监控如下图:
分析
看到Nginx应用占用CPU100%时,第一反应是Nginx服务器作为客户端时创建了大量的TCP连接将随机端口号耗尽,导致Nginx创建新的TCP连接时循环端口号范围寻找不到可用随机端口号造成CPU空载循环,最终CPU高荷载的现象。
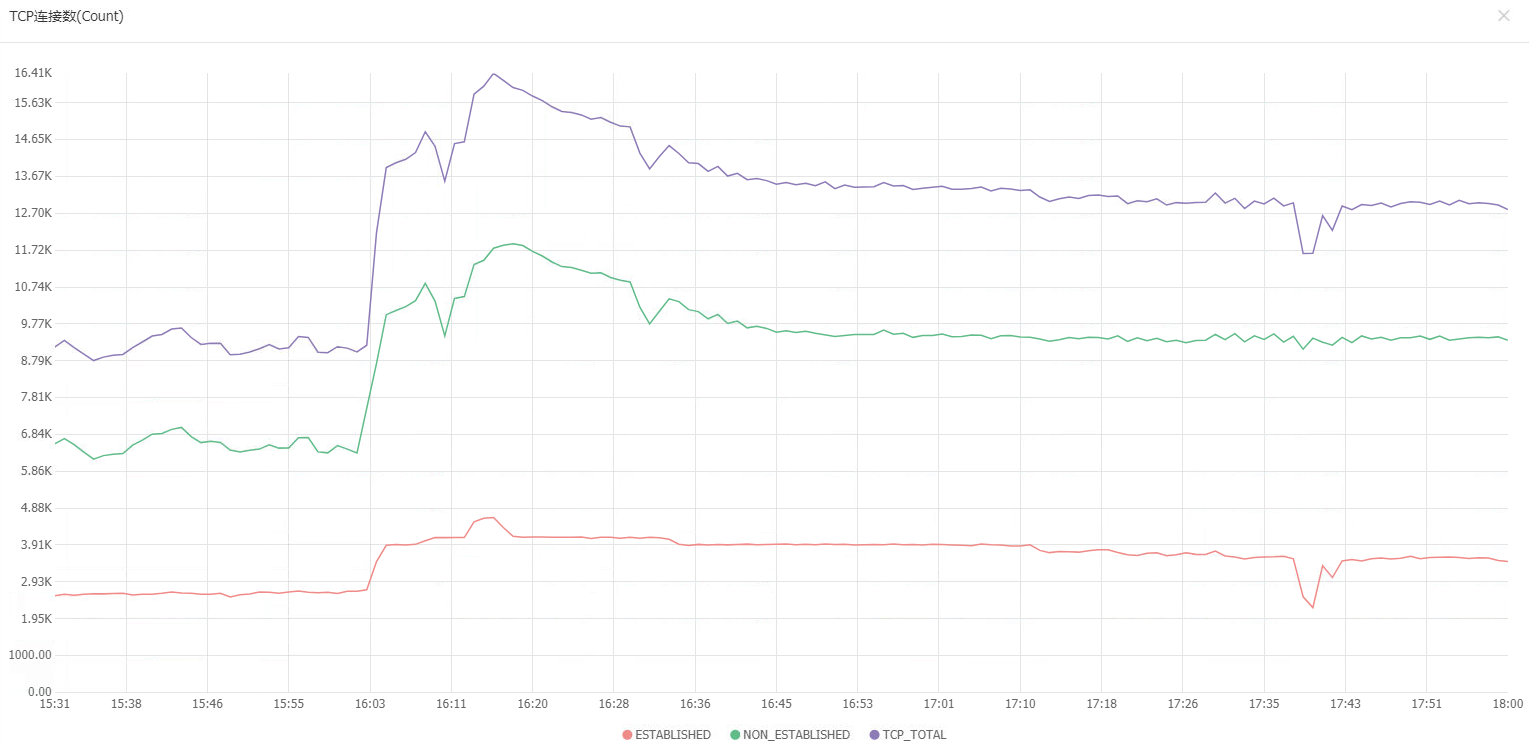
但仔细分析后发现不太可能是这种情况,Nginx服务器的/proc/sys/net/ipv4/ip_local_port_range值为32768 60999即随机端口号范围为32768到60999,合计有28231个随机端口号可以用,而当前监控显示服务器TCP连接最高就一万六千条连接,远远没有到随机端口号耗尽的情况。
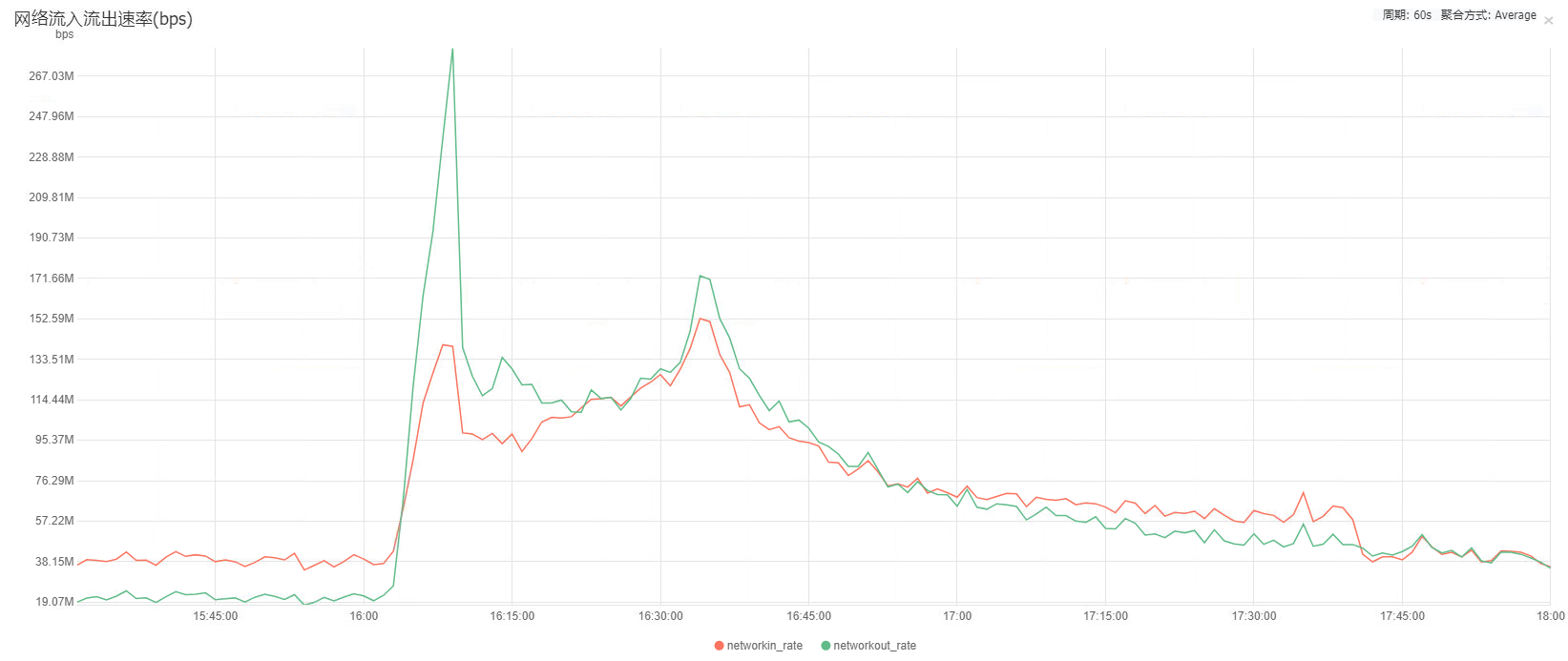
再看Nginx服务器的网络监控,发现宽带流量异常的高,入网和出网均跑到了150M的宽带,对比平时30M左右的流量带宽占用20%左右的CPU资源,150M的带宽导致了100%的CPU合乎情理。因此初步定为是异常流量导致Nginx的高荷载。
后来通过同事了解到,有个商户通过微信公众号推送了我们的一个产品H5页面。想起这个H5每次访问会请求后端一个接口,该接口报文较大大约4K字节,那么导致多占用的120M宽带的接口TPS为120/8/0.004 = 3750即每秒请求三千多次才会导致占用如此之高的宽带。然而事实上,从Nginx日志拉取该H5的访问日志后,分析发现Nginx故障期间该H5的TPS也不过50左右(见下图),显然不是访问该后端接口导致的带宽占用过高。
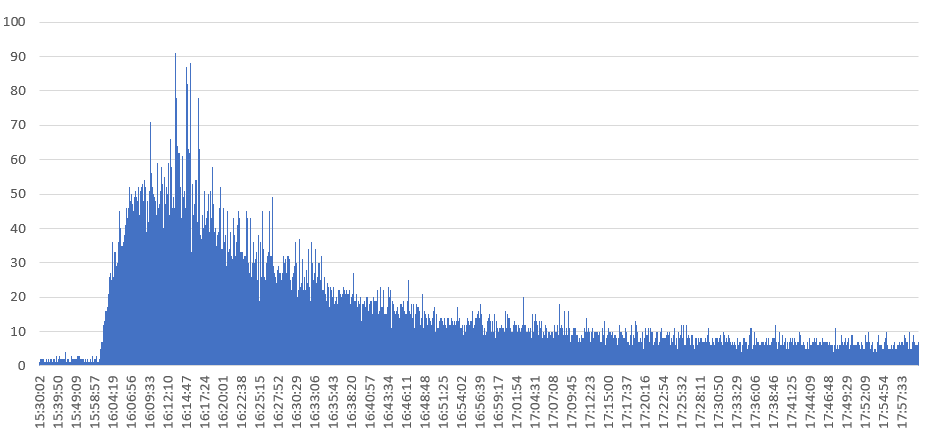
难道是H5页面资源本身的访问导致了宽带占用过高的问题?尝试访问该H5页面后,发现该页面所有的静态文件均在Nginx服务器上,合计大小约300KB。那么TPS50的访问频率大概占用0.3*8*50 = 120即占用120M的带宽,和Nginx服务器的网络资源监控数据相符。
综上,H5页面的静态资源过大占用300KB,当商户通过微信公众号推送该H5页面后,导致H5访问频率过高,TPS50的访问频率占用了120M的网络带宽,直接导致Nginx应用CPU满荷载,进一步造成了后端应用访问Nginx而大量超时异常。
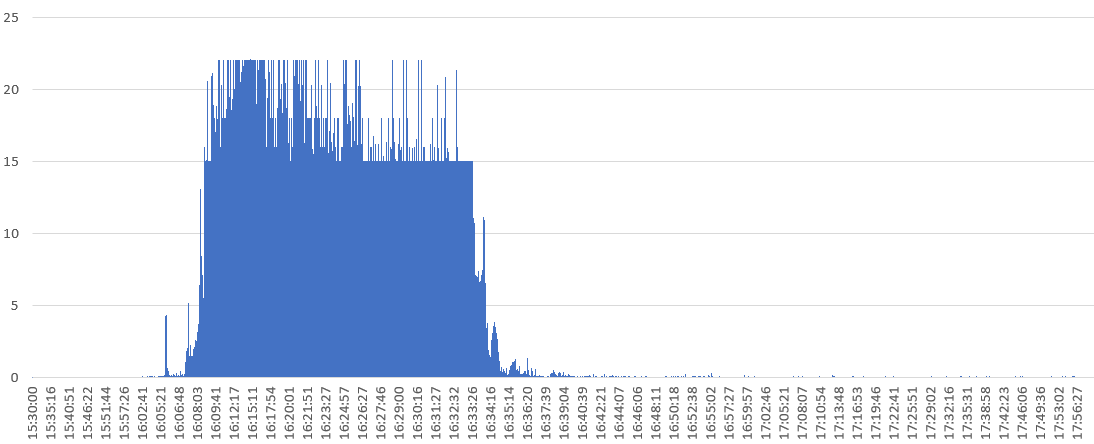
解决
- 将H5页面的静态资源均上传到CDN上,并排查其他前端页面,保证Nginx服务器的网络资源不会被前端静态资源占用过多;
- 对Nginx的日志进行日志收集,可以通过日志分析来快速定位异常的资源访问;