基于券系统分库分表的思考
场景
公司线上环境券系统的用户券码表目前是单表,虽然知道业务增长很快,数据量应该已经很大了。但是由于需求排期很紧,sql查询也没有出现性能瓶颈,也就一直没有给该表安排上分库分表的架构优化。
直到上周某业务需求上线,需要给该表加索引,才发现该表已经增长到不得不进行分库分表的地步了。准备加索引时,习惯性看了一下表数据量,单表磁盘占用20G,总记录5000万条,吓得不敢加索引了,生怕mysql因为给这张表搞索引时宕机了。
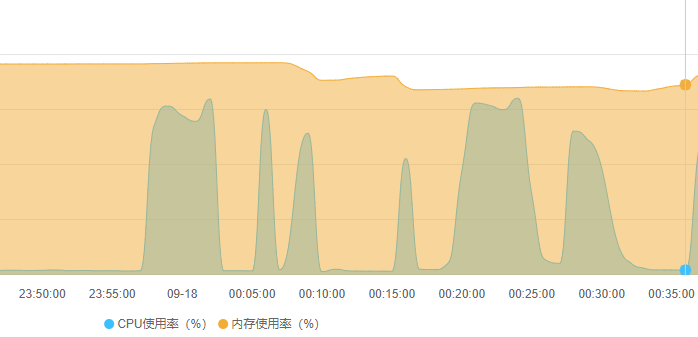
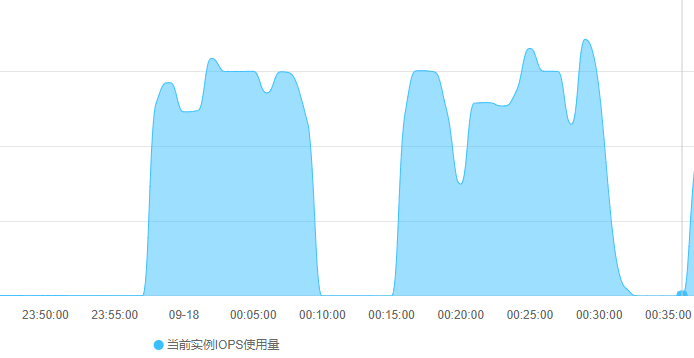
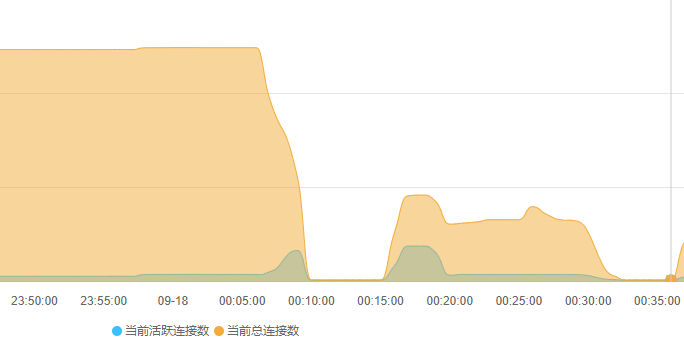
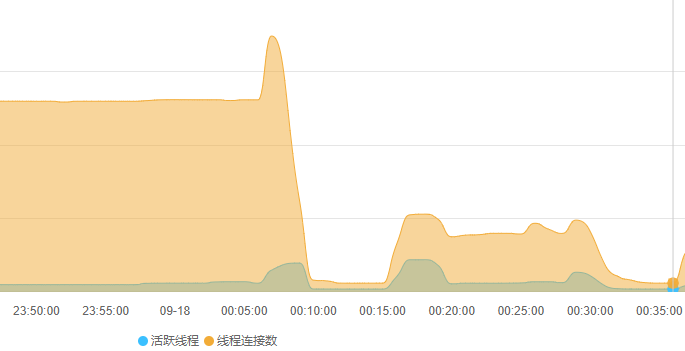
但需求业务要上线,不得不硬着头皮给用户券码表加索引,结果果然在线翻车。索引变更语句执行后,由于mysql的Online DDL机制并没有导致数据库锁表,mysql正常处理该表的读写请求,仅仅从监控上可见CPU和IO飙升(下图23:55:00 ~ 00:10:00)。在索引变更执行15分钟后,突然mysql无响应,该mysql实例所有库所有表的读写请求全部无响应。执行命令show processlist查看mysql的线程发现当前所有线程的状态都是Killed状态,即mysql正在自动杀掉全部线程。很快,mysql恢复正常,但当前所有的连接会话全部中断(包括索引变更也中断了),从监控也可见00:10:00时刻mysql几乎进行了一次软重启。
或许再执行一次就成功了呢?然后就又执行了一次索引变更。15分钟后一模一样的软重启重现后,不再敢变更该表的索引了,直接放弃对应的业务需求上线,准备后续通过业务场景功能的阉割和妥协来避免该索引。
分库分表中间件选型
- Atlas: 只能分表不能分库分实例
- DRDS(现更名为PolarDB-X): 阿里商业服务,功能强大,就是贵
- Mycat: 国产老牌中间件,但官网一言难尽,文档糟糕,社区上的评价褒贬不一
- ShardingSphere: Apache顶级项目,官方文档自带中文且描述详细,社区活跃度高,好评如潮
- TiDB: 配置要求太高,杀鸡用牛刀
对比多个分库分表中间件后,其实更倾向于阿里云的DRDS服务,因为曾经有用过该服务的经验,总体来说对该中间件的印象还是非常不错的,除了价格有点贵。
剔除DRDS后对比了其他几个中间件后,暂定选择Apache的ShardingSphere。一来是Apache的项目,无论是社区活跃度还是项目维护频率都无可挑剔,二是官方文档自带中文,且文档详细,不像Elasticsearch的文档,虽然提供了中文版文档,但是中文版文档却比最新英文文档相差了几年的版本了,还不如不提供。
而ShardingSphere下有ShardingSphere-JDBC和ShardingSphere-Proxy两个成熟的产品,其中前者为Java的加强驱动,限制了客户端语言为java;而后者是个代理中间件,无关客户端语言,因而ShardingSphere-Proxy更适合于我们项目中多语言架构的场景。
ShardingSphere-Proxy目前虽然支持分布式治理,自带配置中心支持和组成中心支持,但是中间件本身还是单点的。一旦节点宕机,则使用该分库分表中间件的所有应用全部不可用。因此为了解决ShardingSphere-Proxy单点的问题,需要引入一个四层反向代理中间件,并且路由规则为基于ip的哈希路由或者更均衡的基于TCP四元组信息的哈希路由,又或者开启TCP会话保持功能。会话保持是为了保证客户端的同一个事务会话连接请求始终路由到同一个ShardingSphere-Proxy节点,保证分布式事务不会因为路由节点切换而错误。
数据分片
在对用户券码表进行业务分析后,确定该表的主要业务场景为读写指定券码和读写指定用户的券码列表,因此最佳的数据分片方案是基于用户ID的数据分片方案。但是基于用户ID的数据分片可以适用于读写指定用户的券码列表,但是对于读写指定券码的场景不太适用。为了解决这个问题,可以针对券码的生成规则进行调整,在券码中隐藏用户ID,当读写指定券码时,先从券码中解析出用户ID,然后通过用户ID和券码两个来读写数据,从而解决数据分片的问题。
券码为字符串类型,规则生成方案如下:
- 固定前缀: 用于区分自有券码、旧数据券码以及第三方导入券码
- 时间戳: 基于某个时间点计算时间毫秒差。以券码作为主键,通过主键排序即为用户领券时间排序,从而减少查询排序的性能消耗
- shardId: 基于用户ID计算出的数据分片值shardId。例如用户ID做哈希后基于1024取模,最终数据分库分表最多分1024个表
- 随机数: 防止券码被猜中
业务调整
分析现有券系统的代码后,券系统的用户券码表的操作有以下:
- 查询指定券码记录
- 插入指定券码记录
- 更新指定券码的记录
- 查询指定用户的券码列表
- 更新指定券模板关联的所有券码的记录
- 查询指定券模板关联的所有券码的记录
- 查询即将过期的券码记录
上述操作中,基于用户ID做数据分片可以适用于前4种读写操作场景,但后3种的数据分片则不适用,会出现对所有分库分表广播的情况。但实际上,由于第5种操作触发频率极低,且每次触发只执行一个SQL语句,因此即使对所有分库分表进行广播的多余性能消耗也能接受。
第7种操作则需要对代码实现方式直接进行重构,不再通过扫描用户券码表来实现,而是新增一个待过期券码表,当用户领券时,如果券模板配置设置该券需要有即将过期提醒,则计算出该券的过期通知时间,将券码和通知时间添加到待过期券码表中。每日固定时间由定时任务扫描待过期券码表,从该表中获取当前需要进行即将过期提醒的券码,并每天凌晨物理删除掉已经通知过期提醒的待通知券码记录。
真正棘手的是第6种场景,具体分析该操作的业务场景,发现主要是用于给商户分析具体活动的用户参与情况,因此对于数据的实时性要求不高。可以通过同步工具将用户券码表的数据同步到数据分析的数据库或者自带数据分片的数据库例如Elasticsearch,以后对于数据的分析和报表全部基于同步后数据库。
导入券码支持
业务不断发展后,时不时会有商户询问这么个问题:能不能将商户自己的券码导入券系统,能不能发放商户自己的券码?
基于上述的分库分表规则,肯定是不能实现导入第三方券码的。因为导入的第三方券码无法基于用户做数据分片,因此如果需要实现该功能,则需要做一层映射关系,将第三方券码映射成自有券码,即需要一个第三方券码和自有券码的映射表。
分析导入第三方券码的业务,如下:
- 导入第三方券码:商户创建券模板规则,然后将第三方券码导入券系统关联该券模板ID。并规定第三方券码的前缀不能与自有券码的前缀相同,以券码前缀来区分是否是第三方券码
- 用户领券: 从第三方券码池中获取指定券模板关联的一个无主第三方券码,生成一个自有券码,将第三方券码和自有券码的映射关系添加到第三方券码与自有券码映射表中,再将自有券码记录添加到用户券码表
- 查用户券列表: 用户券码表中新增一个冗余字段第三方券码,如果自有券码是由第三方券码映射生成的,则在映射券码添加到用户券码表时将原第三方券码值一并补充到该字段中。对前端显示券码时,优先显示第三方券码,非第三方券码才显示自有券码
- 读写指定第三方券码: 通过第三方券码与自有券码映射表先查出该第三方券码映射的自有券码,再通过映射的自有券码去用户券码表读写券记录
第三方券码池表和第三方券码与自有券码映射表在数据量少时可以合并起来,只用一个表实现。毕竟需要导入第三方券码的商户并不多,数据量也不大。商户需要导入的第三方券码一般是商户和某渠道例如电影院之类进行合作,消费送电影票券码。如果需要导入的第三方券码数据量很大,那必然是个大商户,大概率也是使用商户自家的券系统而非使用我们的券系统了。
但是当数据量膨胀需要进行分库分表时,分析上述的第三方券码业务操作,则需要将第三方券码池表和第三方券码与自有券码映射表分割成两个表:
- 第三方券码池表(基于关联的券模板ID哈希取模分片)
- 第三方券码与自有券码映射表(第三方券码哈希取模分片)