数据落盘方案
应用对已存在的文件更新时需要写入数据,当数据写入过程中异常中断例如断电,则会出现数据只写入部分的情况。在这种异常场景下,在应用恢复后对丢失数据的恢复以及避免数据写入未完全导致文件损坏均需要应用保证。
数据储存单元
对于硬盘来说,最小的数据储存单元是扇区,一般为512个字节(现在开始流行4096个字节);而对于操作系统来说,以扇区为读写单位太小效率太慢,所以操作系统以块为数据的读写单位。由此可见,扇区是磁盘的物理结构,而块则是操作系统的抽象逻辑结构,因此块必须是扇区的整数倍。
由下命令可以查看当前环境的扇区大小以及块大小。
1 | [root@VM_0_10_centos ~]# fdisk -l |
其中Sector size则表示硬盘扇区大小为512 bytes。
1 | [root@VM_0_10_centos ~]# df -h |
1 | [root@VM_0_10_centos ~]# tune2fs -l /dev/vda1 | grep 'Block size' |
其中Block size则表示操作系统一个块的大小为4KB,即一个块由连续的8个扇区构成。
数据落盘异常
此处只讨论用户程序应用层面的数据落盘问题,因此假设操作系统可以保证每个块的写入是完整的,即不会出现当数据落盘时突然异常中断,导致一个块写入数据不完成而出现丢失半截数据的情况(比如4KB的块只写进了前1KB的数据,而后续的3KB数据丢失)。
如图,一个文件由N个块组成,程序修改其中的部分数据,向磁盘写入新数据。当程序写入若干个块的数据后,出现中断异常,剩余部分块的数据未成功写入磁盘,导致文件未完整更新而出现文件损坏的情况。
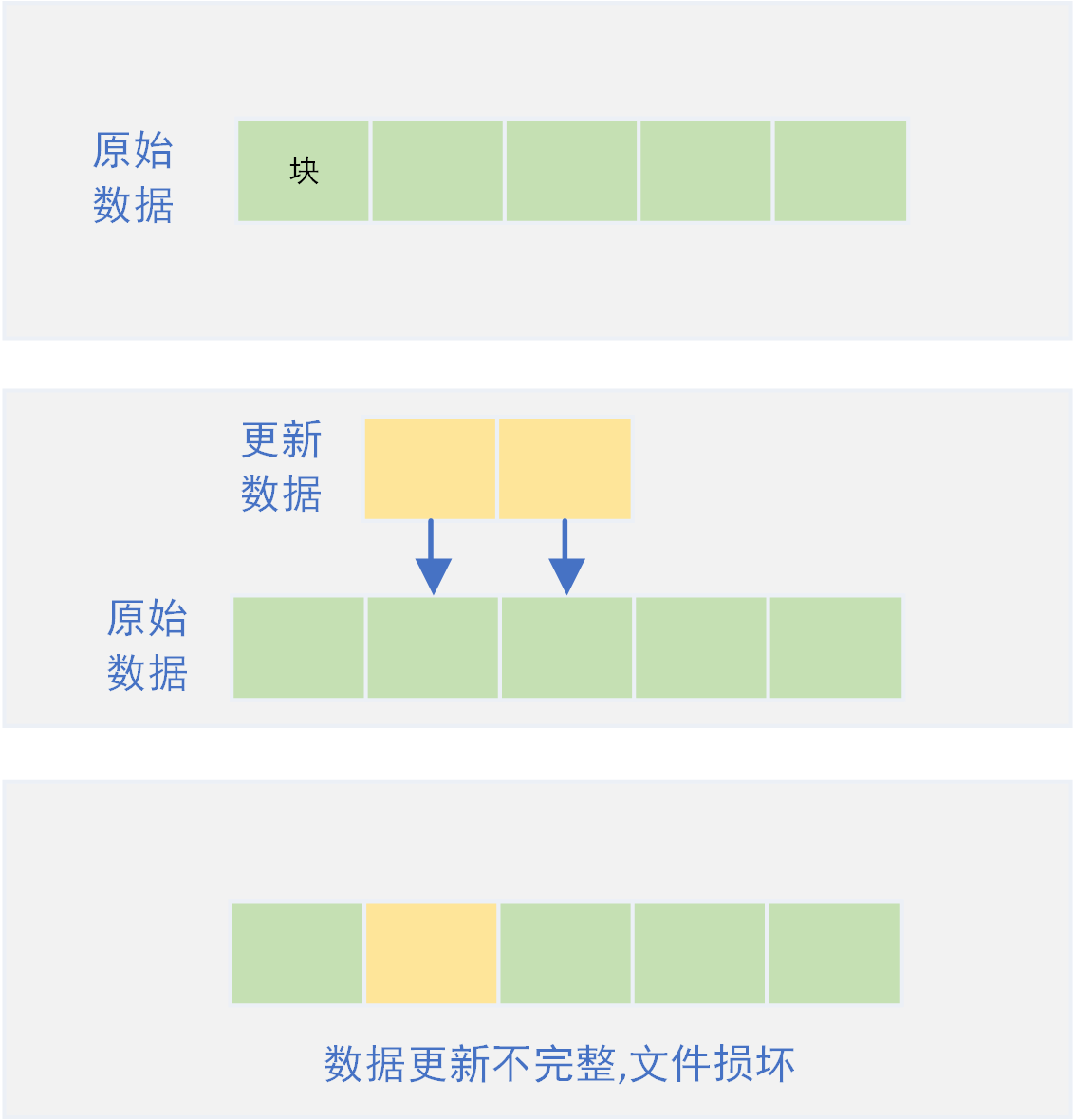
对于该问题的解决,不同场景下有着不同的解决方案。
全量写
全量写即每次写数据时直接重新生成一个新文件,然后通过文件名覆盖原有的旧文件接口。
该方案适用于数据量不大且允许新数据丢失的场景(新文件写入时异常导致新文件生成失败,进而甚至所有新数据丢失),优点是不需要担心新数据写入过程中异常导致旧数据损坏的问题。
比较适合于大多数的数据备份场景,例如redis的RDB快照备份就采用的该方案。如下源码,redis先通过Copy On Write机制将全量RDB文件数据写入到名为temp-%d.rdb的临时文件中,当RDB快照文件全量写入成功后,通过rename的原子操作直接将临时文件重命名覆盖实际的RDB文件。
1 | /* Save the DB on disk. Return C_ERR on error, C_OK on success. */ |
Shadow Paging
影子分页(shadow paging)是一种计算机数据库技术,以实现原子性与持久性。页面在这里指物理存储的单元,可能是在硬盘或内存中,典型为64 KiB。
影子分页是一种写时复制技术,以避免原地修改页面。当一个页面将被修改,一个影子页面被分配。由于影子页面没有被别的地方引用,可以自由修改,不必顾虑一致性。当影子页面变得可以持久,所有引用原页面的地方都被修改为引用影子页面。由于影子页面直到修改完毕才被激活,这保证了原子性。
引用维基百科的解释,Shadow Paging实际上是将操作系统最小的数据单元再抽象成页的概念,一个页由多个连续的块组成,每个页之间通过链表或者索引的方式逻辑连接,而不是物理上的连续。
当某一段数据更新时,则将需要更新的数据所处在的整个页复制到新的页上,所有的数据修改均在新的页上。当数据修改落盘到新的页后,则修改链表指向或者索引即可。
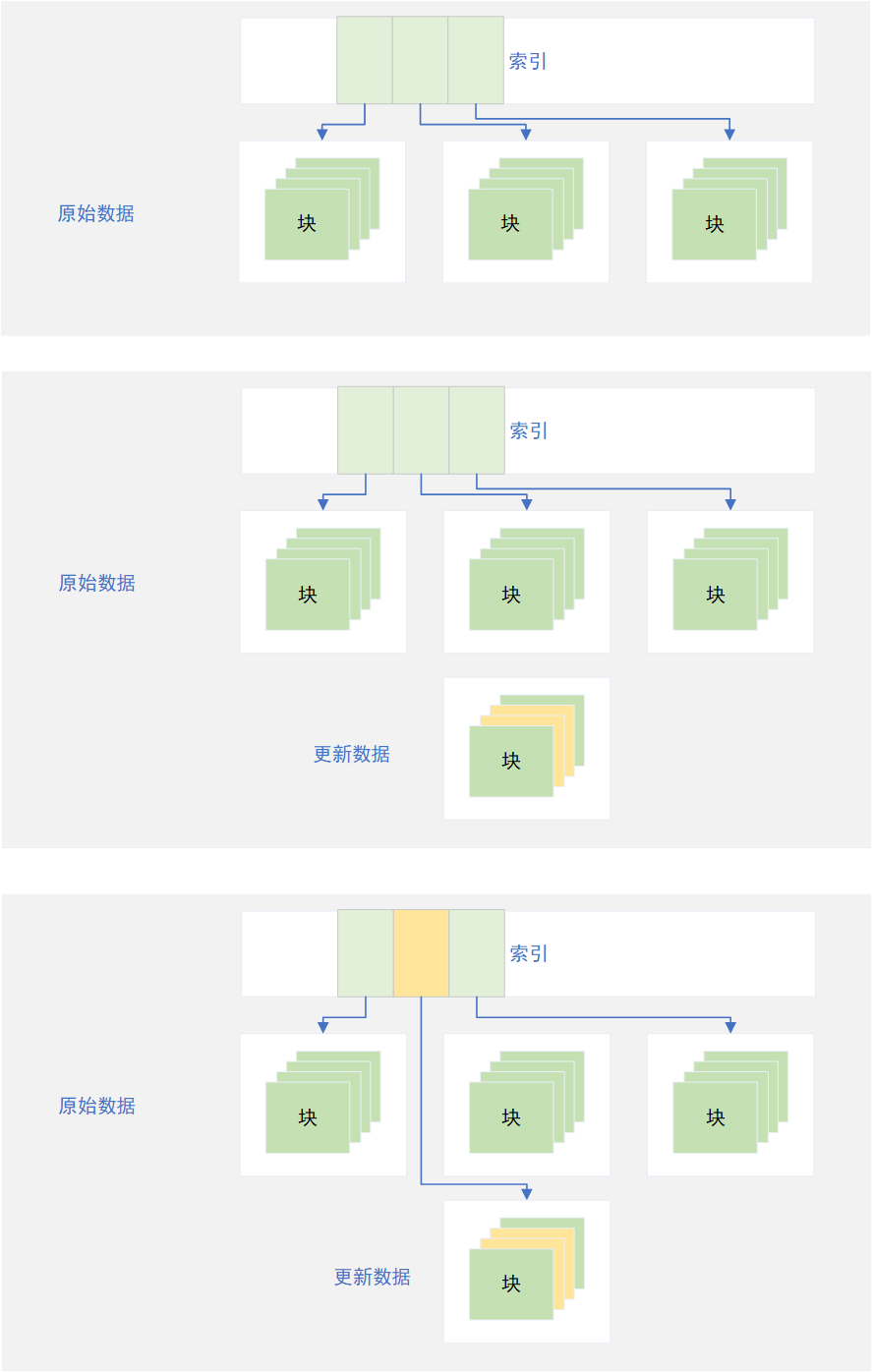
该方案的优点是逻辑简单,缺点也是显而易见:IO浪费太大导致写入性能糟糕(一个少量的数据更新实际需要整个页的数据写入),并且也需要额外的逻辑保证在新的页落盘修改索引前更新数据不会丢失(例如下面的事务日志)。另外,由于数据都是通过链表逻辑连接而在物理层不连续,多次更新后会导致文件的页在物理层的离散度高,每次读写造成大量的随机IO,进一步降低了读写性能。
Double Write
该方案实际上是Shadow Paging的一种优化,最大的优点是每个页从逻辑连续变成了物理连续,避免了随机IO而极大地提高了读写性能。Double Write方案在每次更新数据时,则将需要更新的数据所处在的整个页复制到double write buffer区,所有的数据修改均在double write buffer区的页上。当数据修改落盘到double write buffer区后,则再将更新数据直接写到原始数据的页上。当然,该方案同样可以用在没有页概念的文件修改上,只需要把页的概念替换成更新数据在文件中的偏移量和数据长度即可。
如果新的页落盘double write buffer区后而未落盘原始数据的页时,应用中断导致写失败,则在应用恢复时从double write buffer区找到该页的副本,再重新将更新数据写到原始数据的页上,避免了文件未完整更新而出现文件损坏的情况。
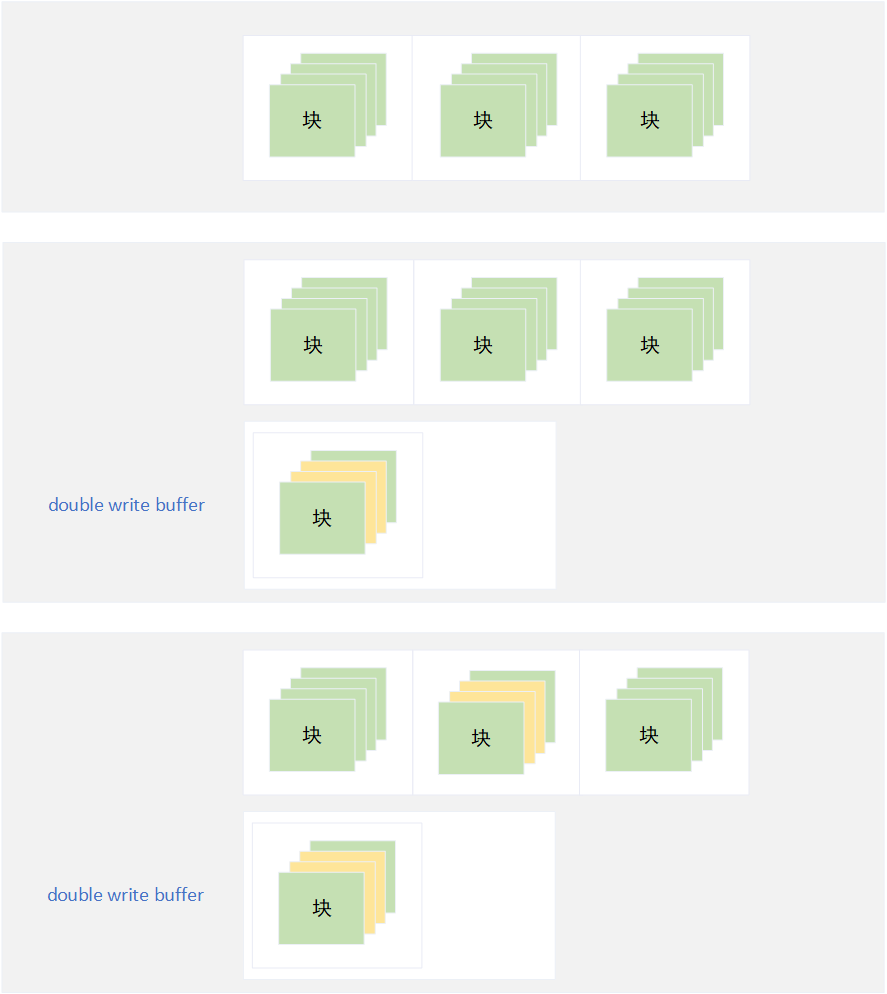
虽然依然会有类似于Shadow Paging方案的IO浪费的问题,但是每次数据页更新后不会改变该数据页在磁盘上的物理位置,避免了随机IO的问题从而极大提高了读写性能,另外该方案同样需要额外的逻辑保证在新的页落盘double write buffer区前更新数据不会丢失(例如下面的事务日志)。
日志
由于顺序IO性能远远高于随机IO,所以通过顺序写数据变更日志来记录下文件数据的变更操作,当应用中断未落盘的数据丢失后,则通过日志来回放数据的变更操作,从而恢复文件数据的最新状态(日志记录需要优先于数据落盘,即Write Ahead Log)。
对于日志记录的数据量,又分为全量日志和增量日志。全量日志即日志中记录了文件数据的全量信息,只需要日志本身就可以完全恢复全部的文件数据;而增量日志,则一般依靠check point,日志中最少记录了check point触发后的文件数据变更日志,即如果需要恢复文件数据,还必须依赖check point触发后的文件数据本身才行。
全量日志

redis的aof就是典型的全量日志,由于全量日志记录了文件数据的所有变更,导致日志文件本身会非常庞大,当应用中断后数据丢失,应用恢复阶段读取日志来重放数据操作的过程会非常耗时。事实上,全量日志不需要记录全量的操作日志,只需要记录每一条数据最后一次的完整日志,但这也意味着应用需要额外的逻辑定时对全量日志进行“瘦身”处理。

优点是日志中记录了全量的数据变更操作,即使原文件数据损坏或者丢失,也可以通过日志来回放出完整的最新文件数据。缺点也是显而易见,日志体积会非常庞大,应用中断后的日志回放恢复耗时也会很久。
增量日志

由于全量日志的文件体积太大,回放耗时长的问题,于是设计出了check point技术,逻辑十分简单:为每一次数据操作添加版本号,数据变更均在内存中执行(数据落盘变成异步操作),并定时将变更后的内存数据批量落盘写到文件,然后已经落盘的旧版本号操作日志从日志文件中删除。因此当应用中断后恢复数据时,需要回放的日志仅仅是高于文件数据版本号的操作日志,不仅大大缩短了回放恢复耗时,也减少了日志的体积。并且,由于数据落盘变成异步操作,可以将一个块的多次IO操作合并成一次IO操作,也极大地提高了应用的性能。
但同样有新的问题出现,该方案必须同时依靠日志和完整的文件数据,如果文件数据本身损坏甚至丢失,则会导致日志回放错误。因此还需要额外的逻辑保证原文件数据更新时避免文件未完整更新而出现文件损坏的情况,例如上述的Shadow Paging和Double Write方案,以及集群环境下,当主节点原文件损坏后拉取从节点未损坏的文件数据也是解决方案之一。