elasticsearch性能优化
1、硬件优化
1.1、 硬件
- 使用固态硬盘储存设备
- 准备足够的内存
- 禁止使用swap交换分区
1.2、 页缓存
elasticsearch查询依赖操作系统的页面高速缓存(File system cache),因此除了需要给elasticsearch的JVM分配足够的内存以外,还需要给页缓存预留内存。
例如单机32G内存,给JVM配置16G内存后,剩余16G预留内存不需要额外配置,也不要让其他进程占用这些内存。预留的16G内存会在elasticsearch读取硬盘时自动分配给页缓存,如下图中的buff/cache栏。

1.3、 节点数
如果资金足够,不要让单节点的数据量超过分配给页缓存的内存大小。如果页缓存的预留内存超过当前节点的数据量,那么该节点的查询操作均在内存中执行,极大提高了elasticsearch的响应速度。
2、分片优化
2.1、 数据冷热分离
对于数据量较大的场景下,热数据存储于SSD而普通历史数据存储机械磁盘。甚至对于日志这类数据,在elasticsearch中只保存需要频繁使用的热数据,极少使用的冷数据可以从elasticsearch中移除而以其他的形式保存,减少elasticsearch的查询聚合压力。
例如使用elasticsearch存储日志,可以以日期名称作为index名,每天以一个新的index保存当天的日志数据。对于超过3个月或者半年的日志,直接删除index,而把这些冷数据保存到文件中封存。
2.2、 routing
elasticsearch每个index默认创建5个shard数据分片,当创建一个新文档时,该文档存储到的分片通过以下公式计算:
1 | shard = hash(routing) % number_of_primary_shards |
routing是一个可变值,默认是文档的_id。因此文档会均匀分布到创建的shard分片上。
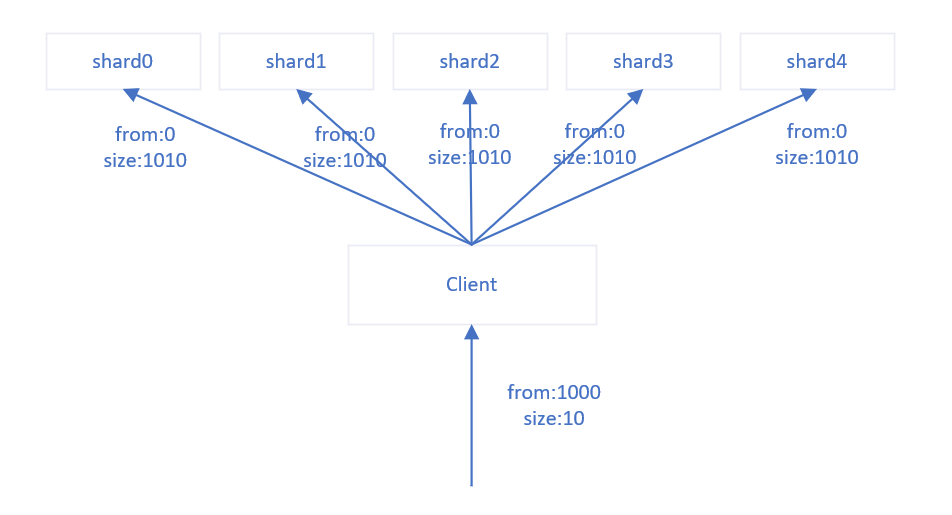
当用户对文档进行非id的查询时,由于文档可能存放在任意一个shard分片上,所以需要对每一个shard分片进行一个查询后,再对所有shard分片返回的查询结果进行聚合。该过程将浪费大量的网络资源、CPU资源和IO资源。
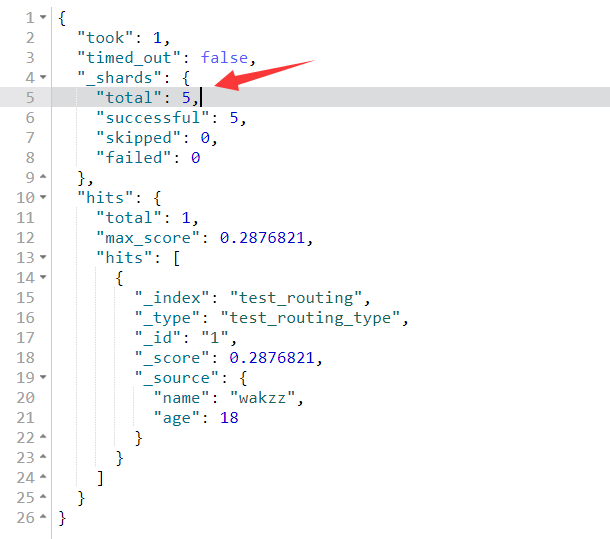
1 | PUT /test_routing/test_routing_type/1 |
用户可以通过指定routing将相同routing的文档存放到同一个shard分片上,那么当通过routing查询文档时,通过routing可以直接定位到一个shard分片,而不需要对每一个shard分片请求,节约了大量的资源。
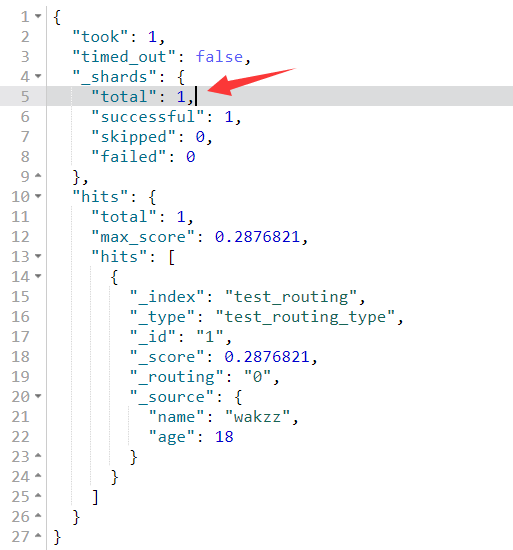
1 | PUT /test_routing/test_routing_type/1?routing=0 |
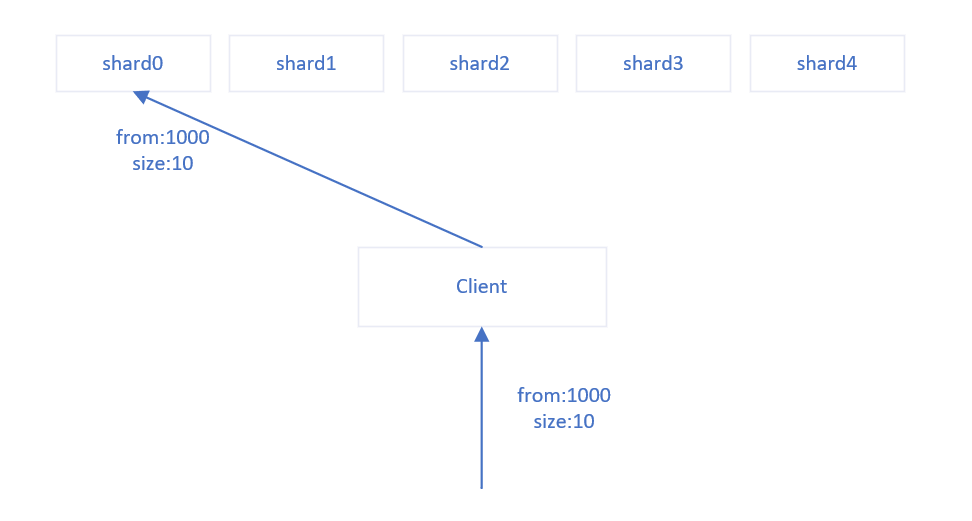
routing需要针对业务场景而确定,例如在租户模式下,绝大多数操作都是对租户下的数据进行增删改查,很少有跨租户的操作。该业务场景就可以用租户ID作为routing。
3、DSL优化
- 避免模糊查询(
wildcard) - 只对日期和数值字段范围查询
- 避免在查询条件中使用script