mysql索引原理
页分裂
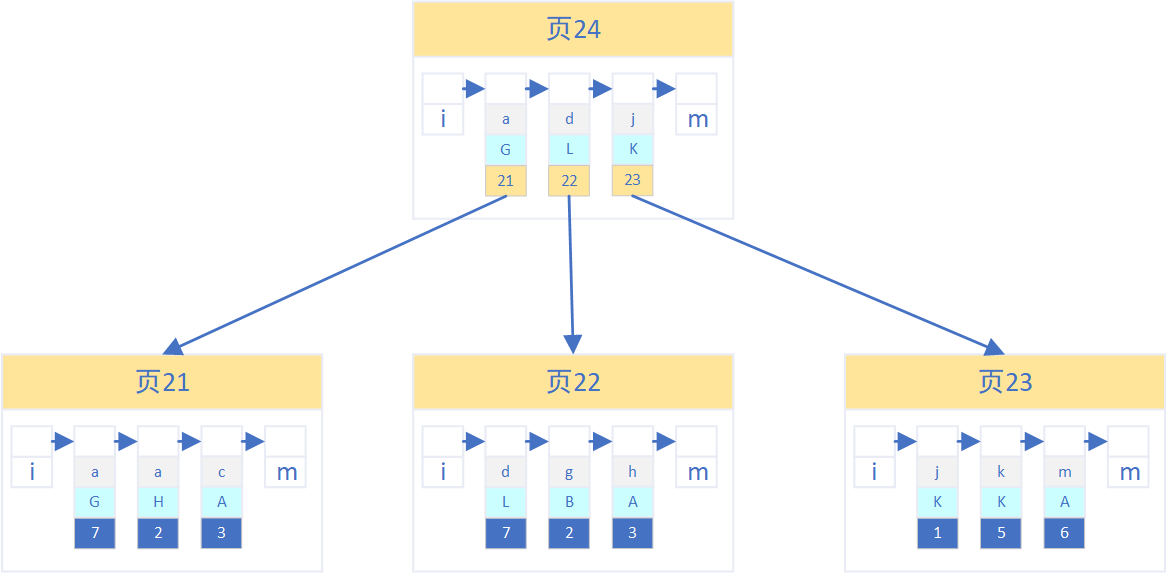
每个数据页的开头记录了当前页的编号以及该数据页的上一页和下一页的编号,如图:
- 1-4字节为当前数据页数据的校验和;
- 5-8字节为当前数据页的编号;
- 9-12字节为上一个数据页的编号;
- 13-16字节为下一个数据页的编号;
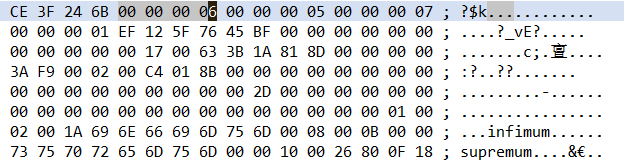
即数据页以一个双向链表维持着顺序,每个数据页中以单向链表的格式对记录的RowID进行逻辑排序,并且每个数据页之间的记录进行物理排序(页编码大的数据页中的记录RowID必须大于页编码小的数据页的记录RowID)。
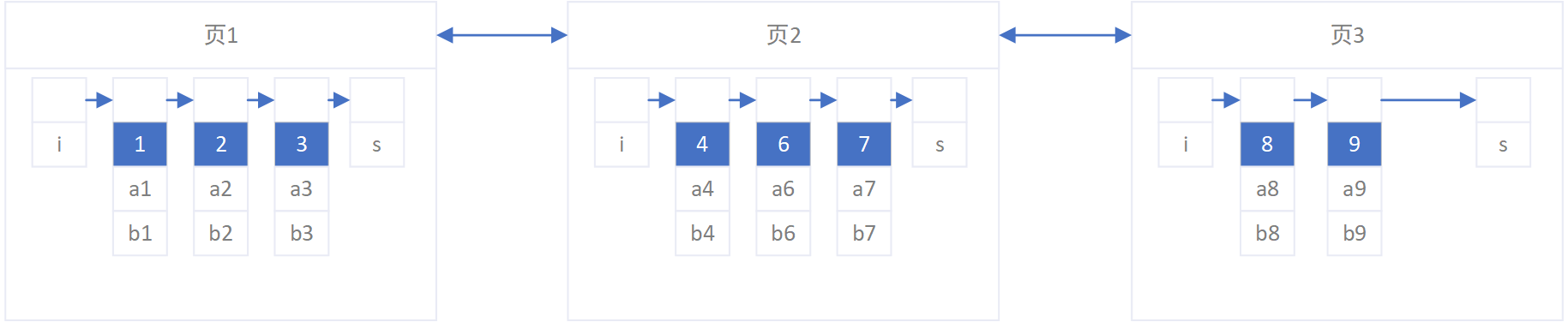
由于每个数据页之间的记录都是按RowID物理排序的,因此存在向一个满数据的页插入新记录的情况,如上图。页2已经满数据,再插入ID为5的记录时,按顺序应该插入页2,但此时页2已经无法再插入新数据,则需要创建一个新的数据页存放页2一半的记录,并将该新的数据页放在页2和页3之间,该操作叫做拆页,如下图。
频繁的乱序ID插入会造成频繁的拆页操作,导致大量的IO操作降低mysql的性能,因此mysql推荐使用自增长ID来减少拆页操作,这也是主流的分布式ID生成器生成的id是趋势递增的原因。

聚集索引
如果数据页之间单单以双向链表进行连接,那么每次查询一个指定RowID的记录时,都需要从第一个数据页开始顺着链表扫描数据页,即每次查询都是一个扫表操作。因此InnoDB对数据页进行了目录项记录,把每个数据页的第一条记录的RowID放到一个索引页中,作为目录使用。每一个目录记录存放RowID和该RowID对应的页编号。当数据页足够多,导致作为目录的第二层索引页的数量也很多时,再对第二层索引页进行目录项记录,即目录的目录。最终组成的一个树形结构就是聚集索引。
聚集索引使用树是B+树,相对于hash树,优点在于RowID按顺序排序,可以用于范围查询;而相对于二叉树,B+树每个树节点可以容纳多个值,并且可以通过拆页以及页左右平移减少大量的树平衡操作,减少了IO消耗。另外在innodb中B+树的树高度一般在2 ~ 4层,也就是说查询指定RowID的记录时最多只需要2 ~ 4次的IO。
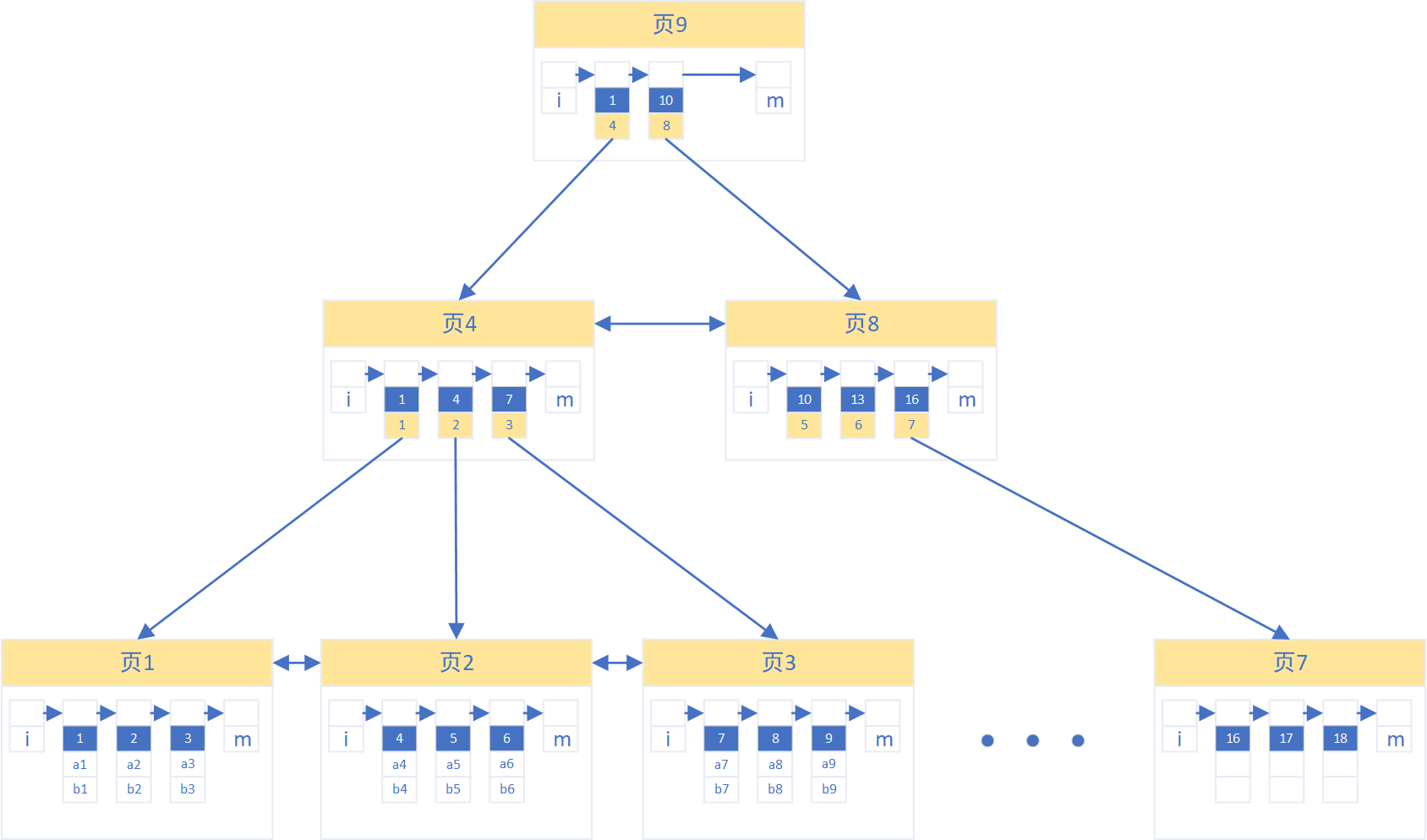
通过聚集索引,每次查询一个指定RowID的记录时,从聚集索引的顶端开始依次找到下一级对应的页编号,直到最终找到该记录所在的数据页,再通过Page Directory对数据页中的记录进行二分法查找到真正的记录行。
单列索引
为了提高指定字段的查询效率,可以对该字段创建一个单列索引。单列索引在结构上与聚集索引差别不大:
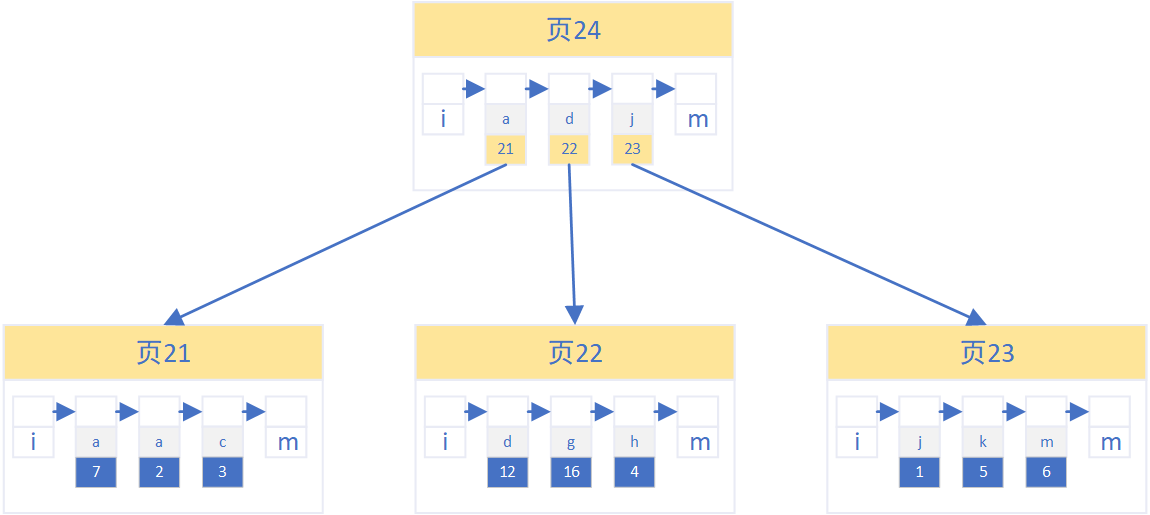
- 聚集索引的树节点存放着RowID和页编号;单列索引的树节点则存放着索引字段的值和页编号
- 聚集索引的叶子节点是记录的数据页,保存着完整的记录行;单列索引的叶子节点存放着索引字段的值和对应记录的RowID
由于单列索引的叶子节点并没有完整的记录行,只有记录行的RowID,因此通过单列索引查询记录最后只能获取到符合条件索引字段条件的记录的RowID。如果还需要查询除了RowID和索引字段以外更多的列的值时,则需要通过RowID再使用聚集索引找到完整的记录行,通过RowID再查询记录的操作叫回表。相反如果查询只需要RowID和索引字段则不需要回表操作,直接从当前索引中获取值返回,该操作叫索引覆盖。
单列索引中RowID不是顺序的,因此每一次回表实际上都是一次随机IO。如果一次查询中出现大量记录的回表操作,则会造成大量的IO消耗,甚至出现mysql为了减少回表而拒绝使用该索引的情况。
组合索引
组合索引和单列索引本质上一样,仅仅是原先的单列索引上的每一条记录仅存放单个索引列的值和RowID,而组合索引则索引上的每一条记录存放多个索引列的值和RowID。
对多个字段建立组合索引后,索引记录之间以索引字段顺序先对第一个字段排序,第一个字段相同时再对第二个字段排序,依次往后。因此如果使用组合索引,必须按照索引字段的顺序查询字段,例如B、A、C三个字段建立组合索引,where A = a1 and B = b1 andC = c1可以使用该索引,但如果where A = a1 and C = c1则无法使用该组合索引。这就是组合索引的最左匹配原则。
回表
非聚集索引的索引树的节点都是按照索引字段的值排序的,而对应记录的的RowID是无序排序的,因此每次通过非聚集索引找到记录的RowID后,还需要通过RowID去查询真正的记录行的回表操作是一个随机IO。一旦通过非聚集索引范围查询获取的RowID的数量较大时,回表操作所进行的大量随机IO的性能消耗将相当可观。
对于InnoDB来说,当一次查询需要回表的记录数量足够多(可以简单地理解为总记录数的20%左右),InnoDB会计算出性能消耗认为如此多回表操作导致的随机IO消耗会比直接全表扫描的顺序IO消耗还高,而导致宁可不走索引直接全表扫描也不使用导致如此数量回表操作的索引。
为了避免以上的情况,一般有两种方案:
- 索引覆盖
- 减少回表记录数量
索引覆盖就是一次查询中所需要的字段均为非聚集索引树中的索引字段,那么这次查询直接从非聚集索引树中直接获取字段值而不需要回表操作。例如A、B、C三个字段建立组合索引,select A, B, C from table where A = a1 and B = b1需要查询的A、B、C三个字段的值都已经在组合索引中,就不必到聚簇索引中再查找记录行了。
索引覆盖可以彻底告别回表的性能问题,大大提升查询性能,当然相对的,为了维护索引树也降低了增删改操作的性能。