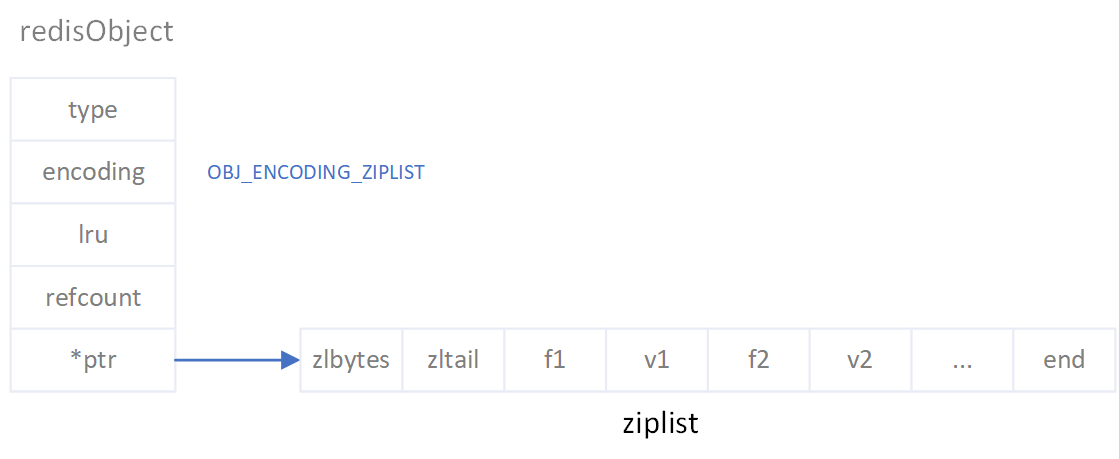
# Hashes are encoded using a memory efficient data structure when they have a # small number of entries, and the biggest entry does not exceed a given # threshold. These thresholds can be configured using the following directives. hash-max-ziplist-entries 512 hash-max-ziplist-value 64
127.0.0.1:6379> hset members f1 1234567890123456789012345678901234567890123456789012345678901234 (integer) 1 127.0.0.1:6379> debug object members Value at:0x7fe27c2b3490 refcount:1 encoding:ziplist serializedlength:38 lru:2137862 lru_seconds_idle:3
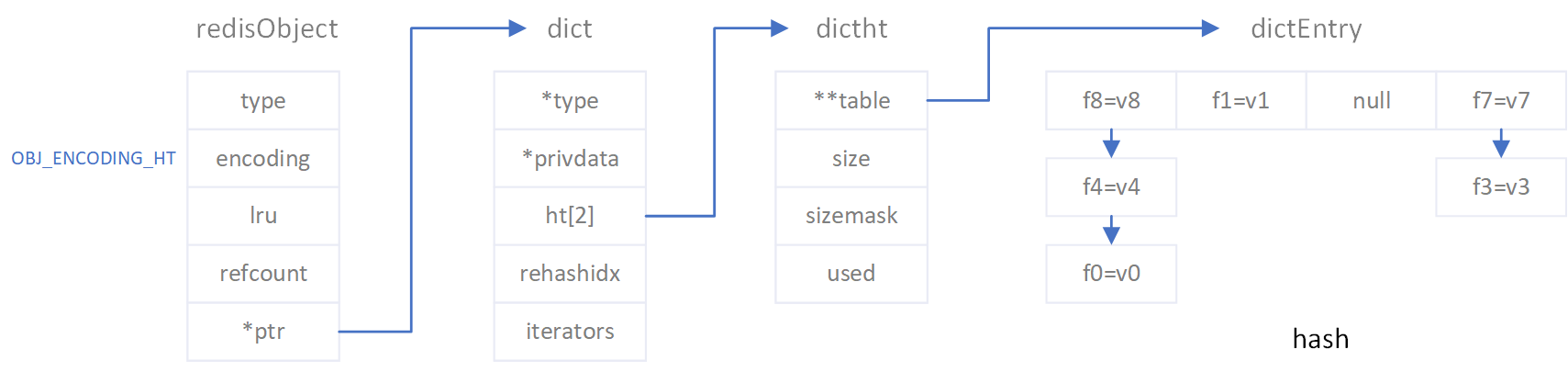
127.0.0.1:6379> hset members f1 12345678901234567890123456789012345678901234567890123456789012345 (integer) 0 127.0.0.1:6379> debug object members Value at:0x7fe27c2b3490 refcount:1 encoding:hashtable serializedlength:26 lru:2137871 lru_seconds_idle:6
关键源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13
inthashTypeSet(robj *o, sds field, sds value, int flags){ int update = 0;
if (o->encoding == OBJ_ENCODING_ZIPLIST) { ... // 当存放的键值对数量大于hash-max-ziplist-entries时转换编码 /* Check if the ziplist needs to be converted to a hash table */ if (hashTypeLength(o) > server.hash_max_ziplist_entries) hashTypeConvert(o, OBJ_ENCODING_HT); } ... }
/* This is our hash table structure. Every dictionary has two of this as we * implement incremental rehashing, for the old to the new table. */ typedefstructdictht { dictEntry **table; unsignedlong size; // 哈希表table的大小 unsignedlong sizemask; // 用于位运算计算key对应的table位置,sizemask=size-1 unsignedlong used; // 哈希表中键值对的数量 } dictht;
typedefstructdict { dictType *type; void *privdata; dictht ht[2]; long rehashidx; // 表示rehash时hash槽下次迁移数据的槽的位置,-1表示非rehash状态 unsignedlong iterators; /* number of iterators currently running */ } dict;