mysql回表致索引失效
简介
mysql的innodb引擎查询记录时在无法使用索引覆盖的场景下,需要做回表操作获取记录的所需字段。
mysql执行sql前会执行sql优化、索引选择等操作,mysql会预估各个索引所需要的查询代价以及不走索引所需要的查询代价,从中选择一个mysql认为代价最小的方式进行sql查询操作。而在回表数据量比较大时,经常会出现mysql对回表操作查询代价预估代价过大而导致索引使用错误的情况。
案例
示例如下,在5.6版本的mysql、1CPU2G内存的Linux环境下,新建一个测试表,并创建将近200万的记录用于测试。
1 | CREATE TABLE `salary_static` ( |
1 | delimiter // |
测试数据创建完成后,执行以下sql语句进行统计查询。
1 | select school_id,avg(salary) from salary_static where year between 2016 and 2019 group by school_id; |
预计该sql应该使用year_school_key索引进行查询,但实际上通过explain命令可以发现,该sql使用的是school_id_key索引,并且由于使用了错误的索引,该sql进行了全表扫描导致查询时间花费了7秒。


强制使用year_school_key索引进行查询后发现,该sql的查询时间花费锐减到了0.6秒,比起school_id_key索引的时间减少了10倍。
1 | select school_id,avg(salary) from salary_static force index(year_school_key) where year between 2015 and 2019 group by school_id; |


分析
使用mysql的optimizer tracing(mysql5.6版本开始支持)功能来分析sql的执行计划:
1 | SET optimizer_trace="enabled=on"; |
输出的结果为一个json,展示了该sql在mysql内部的sql优化过程、索引选择过程的执行计划。
重点关注执行计划的json中range_analysis下的内容,这里展示了where范围查询过程中索引选择。table_scan表示全表扫描,预估需要扫描1973546条记录,但是由于全表扫描走聚集索引是顺序IO读,因此每条记录的查询成本很小,最终计算出来的查询成本为399741。range_scan_alternatives表示使用索引的范围查询,year_school_key索引预估需要扫描812174条记录,但是由于需要回表操作导致随机IO读,最终计算出来的查询成本为974610。所以对于where查询过程最终选择全表扫描不走索引。
1 | "range_analysis": { |
这里的查询成本cost值完全可以手算出来,cost=I/O成本(每一次读取记录页一次成本,每次成本为1.0)+CPU成本(每一条记录一次成本,每次成本为0.2)。
全表扫描查询成本
table_scan全表扫描时预估需要扫描1973546条记录,通过show table status like "salary_static"命令可得全表记录为82411520字节(Data_length),innodb每个记录页为16KB即全表扫描需要读取82411520/1024/16 = 5030个记录页。
I/O成本1
5030 * 1.0 = 5030
CPU成本1
1973546 * 0.2 = 394709.2
合计查询成本
1
5030 + 394709.2 = 399739.2
索引查询成本
year_school_key索引时预估需要扫描812174条记录,且使用该索引需要先通过索引查询到rowId,然后通过rowId回表。mysql认为每次回表均需要一次单独的I/O成本
CPU成本1
812174 * 0.2 = 162434.8
I/O成本1
812174 * 1.0 = 812174
合计查询成本
1
162434.8 + 812174 = 974608.8
接着再关注reconsidering_access_paths_for_index_ordering,表示最终对排序再进行一次索引选择优化。这里选择了school_id_key索引并且一票否决了上面where条件选择的全表扫描:"plan_changed": true,详见group-by-optimization。
1 | { |
事实上排序索引优化也存在bug,详见Bug#93845。
优化
通过分析sql执行过程,可以发现选择索引错误的是因为year_school_key索引回表记录太多导致预估查询成本大于全表扫描最终选择了错误的索引。
因此减少该sql的执行时间,下一步的优化方案是减少该sql的回表操作,即让该sql进行索引覆盖。该sql涉及到的字段只有school_id、salary和year这3个字段,因此创建这3个索引的联合索引,并注意这3个字段在联合索引中的顺序:where过滤语句最先执行,所以year字段在联合索引第一位;group by语句本质上和order by一样,因此排在where后面即联合索引第二位;salary仅仅为了减少回表因此放在联合索引末位。
1 | CREATE INDEX year_school_salary_key ON salary_static (year, school_id, salary); |
在创建了联合索引后,再执行sql语句后效果如下,仅花费了0.2秒完成查询,比起school_id_key索引的时间减少了35倍。

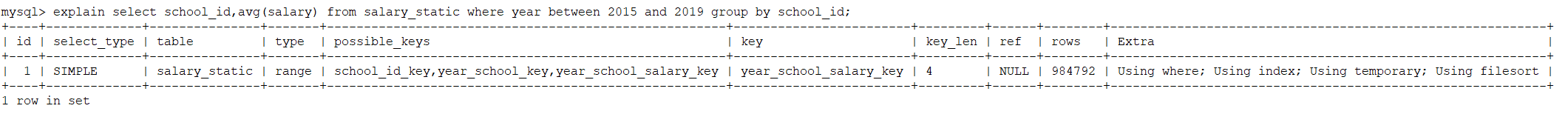
回表率计算
上述问题为sql一次性查询数量太多,导致回表代价太大。事实上,上述现象的临界值完全可以计算出来:
假设一行记录的大小为a字节,表的记录数量为b,临界记录数量为c,则该表的记录页数量为b*a/1024/16
1 | 全表扫描的查询成本 = I/O成本 + CPU成本 |
即当一条sql查询超过表中超过大概17%的记录且不能使用覆盖索引时,会出现索引的回表代价太大而选择全表扫描的现象。且这个比例随着单行记录的字节大小的增加而略微增大。