kafka架构概念
Broker
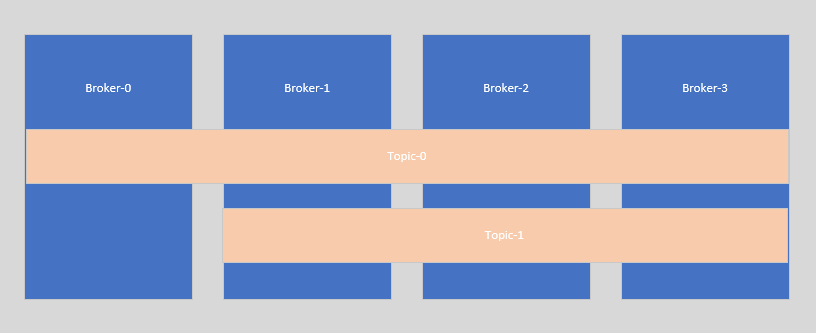
每一个kafka的服务都是一个Broker,一个集群由多个Broker组成。Broker与topic的副本的关系是一个Broker可能存在多个topic的副本,一个topic的副本可能存在于多个Broker上。
如下图:Topic-0通过--replication-factor参数创建了4个副本保存在4个Broker上,Topic-1通过--replication-factor参数创建了3个副本保存在3个Broker上。
Topic
Topic就是数据主题,是数据记录发布的地方,可以用来区分业务系统。Kafka中的Topics总是多订阅者模式,一个topic可以拥有一个或者多个消费者来订阅它的数据。
topic是物理层面的概念,在路径/tmp/kafka-logs(配置文件server.properties的log.dirs值)下可以看到每个topic对应至少一个文件夹。如下,名为test的topic对应文件夹test-0,名为test-topic的topic对应文件夹test-topic-0、test-topic-1、test-topic-2。
1 | drwxr-xr-x. 2 root root 178 Jan 26 22:43 test-0 |
创建topic时可以通过--replication-factor设置副本数量。当topic有多个副本时,则有多个Broker拥有该topic的副本,这些Broker会有1个leader负责读写数据,其他的Broker均为folllower负责从leader同步数据。当leader所在Broker宕机后,剩余的follower选取出一个Broker作为新的leader负责读写数据,保证kafka机器的高可用。
__consumer_offsets
__consumer_offsets是一个kafka的内部topic,存放了Consumer group组元数据消息和Consumer group的offset位移消息。
用户感知不到该topic的存在。但是可以在路径/tmp/kafka-logs(配置文件server.properties的log.dirs值)下看到该topic的存在,如下:
1 | drwxr-xr-x. 2 root root 141 Jan 26 22:43 __consumer_offsets-0 |
配置文件server.properties中__consumer_offsets的副本数量默认为1,这会导致一个问题:即使用户使用的topic通过--replication-factor参数设置了多个副本,当__consumer_offsets当前副本所在的broker宕机,由于__consumer_offsets只有一份副本,那么消费者就无法读取和写入topic的offset位移信息,从而导致生产者可以发送消息但消费者不可用。
因此在kafka集群中offsets.topic.replication.factor务必设置大于1。
1 | ############################# Internal Topic Settings ############################# |
Partition
对于每一个topic拥有至少一个partition,如下所示:
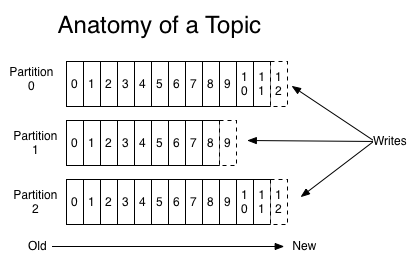
partition同样也是是物理层面的概念,一个topic分成一个或多个partition,每个partition有多个副本分布在不同的broker中。如下,名为test的topic对应文件夹test-0即该topic拥有1一个partition;名为test-topic的topic对应文件夹test-topic-0、test-topic-1、test-topic-2即该topic拥有3个partition。
1 | drwxr-xr-x. 2 root root 178 Jan 26 22:43 test-0 |
生产者向topic的partition发送数据后,数据会按顺序追加到该partition末尾。因此,当消费者消息从topic消费数据时,对于同一个partition的数据消费是绝对有序的,但不保证一个topic的整体(多个partition间)的数据消费顺序。
Offset
Kafka的topic被分割成了一组完全有序的partition,其中每一个partition在任意给定的时间内只能被每个订阅了这个topic的consumer组中的一个consumer消费。这意味着partition中每一个consumer的位置仅仅是一个数字,即下一条要消费的消息的offset。这使得被消费的消息的状态信息相当少,每个partition只需要一个数字。这个状态信息还可以作为周期性的checkpoint。这以非常低的代价实现了和消息确认机制等同的效果。
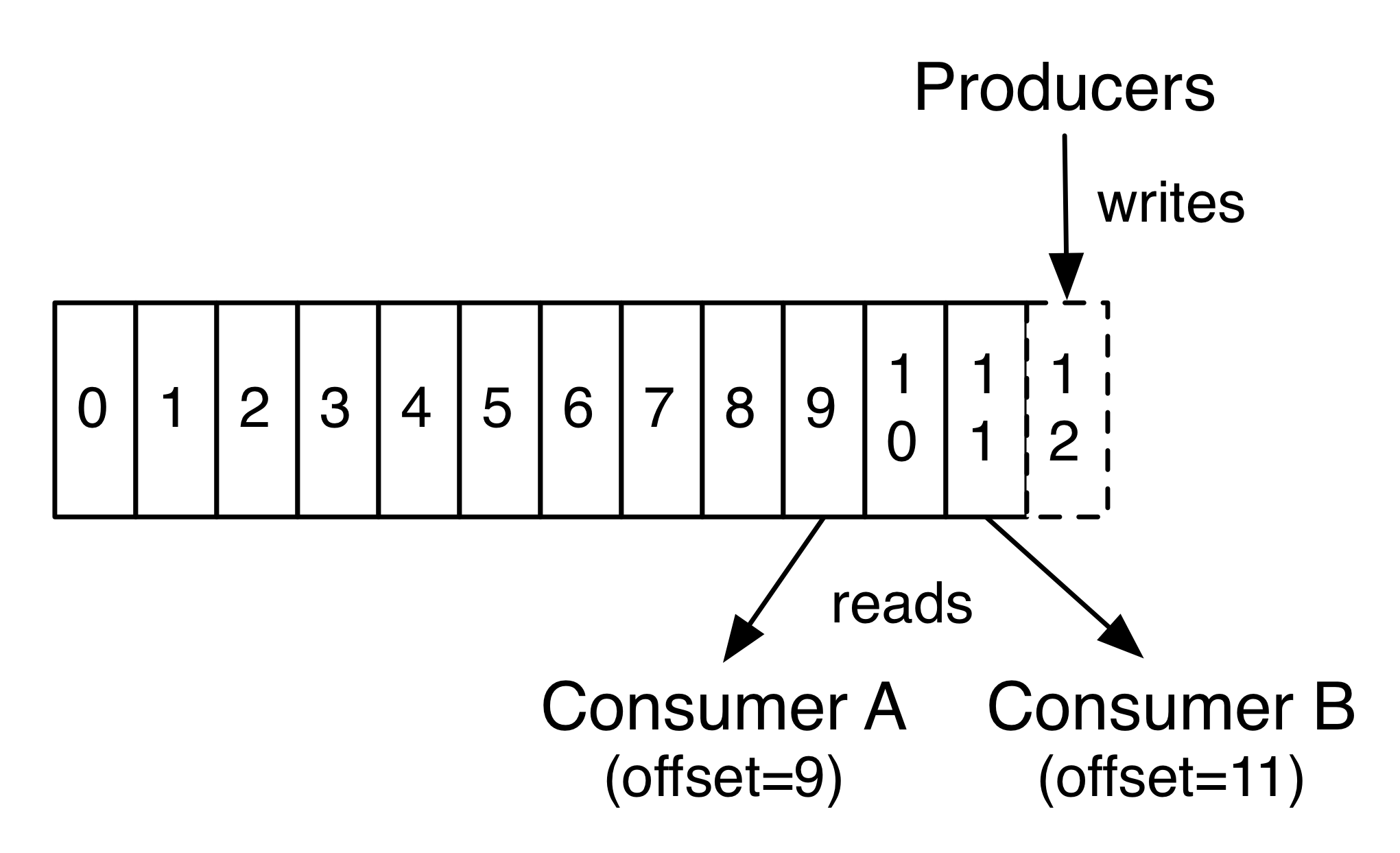
这种方式还有一个附加的好处。consumer 可以回退到之前的offset 来再次消费之前的数据,这个操作违反了队列的基本原则,但事实证明对大多数 consumer 来说这是一个必不可少的特性。
例如,如果 consumer的代码有bug,并且在bug被发现前已经有一部分数据被消费了,那么 consumer 可以在 bug 修复后通过回退到之前的 offset来再次消费这些数据。
Producer
Producer为生产者,负责将消息发送到kafka的指定topic的指定partition中。如果发送的消息存在key值,则生产者使用partition数量对key值取模后发送到对应的partition中;如果发送的消息不存在key值,则生产者向消息投放到随机的partition中。
如下java客户端的实现org.apache.kafka.clients.producer.internals.DefaultPartitioner:
1 | public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) { |
Consumer
Kafka采取拉取模型(poll),由消费者控制消费速度,以及消费的进度,消费者可以按照任意的偏移量进行消费。比如消费者可以消费已经消费过的消息进行重新处理,或者消费最近的消息等等。
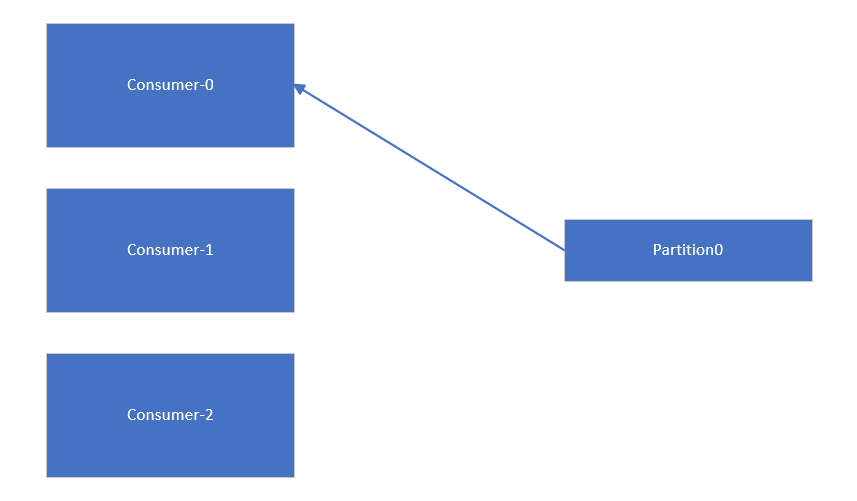
消费者与partition的关系是一个partition同时只能被每个订阅了这个topic的consumer组中的一个consumer消费。当partition的数量不小于消费者数量时,消费者与partition关系图如下:

当partition的数量小于消费者数量时,消费者与partition关系图如下。由于一个partition同时只能由消费组中的一个消费者消费数据,这种情况下会导致其他消费者闲置,无法从kafka消费到数据。因此在创建topic时一定要确定好partition数量(partition不小于消费者数量)。
ConsumerGroup
每个consumer属于一个特定的ConsumerGroup,可为每个consumer指定ConsumerGroup,若不指定,则属于默认的group。一条消息可以发送到不同的ConsumerGroup,但一个ConsumerGroup中只能有一个consumer能消费这条消息。
这是kafka用来实现一个topic消息的广播(发给所有的consumer)和单播(发给任意一个consumer)的方法。