JVM问题分析处理手册
转载自知乎本文链接地址: JVM问题分析处理手册
一.前言
各位开发和运维同学,在项目实施落地的过程中,尤其是使用EDAS、DRDS、MQ这些java中间件时,肯定会遇到不少JAVA程序运行和JVM的问题。我结合过去遇到的各种各样的问题和实际处理经验,总结了JAVA问题的处理方式,希望能帮助到大家。
二.问题处理总体概括
如下图所示: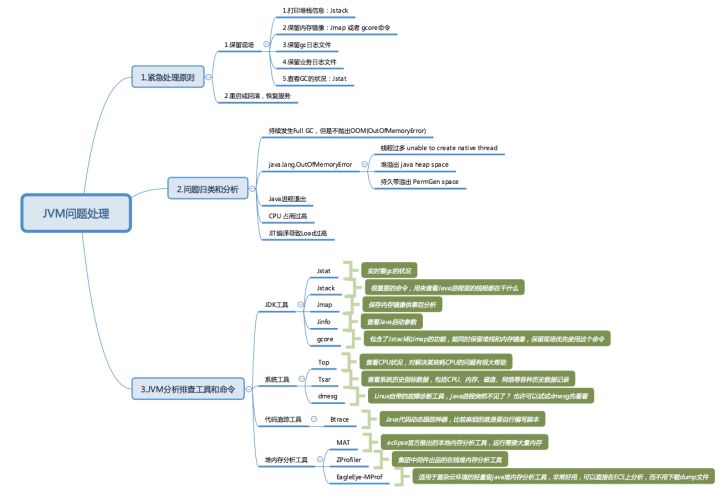
问题处理分为三大类:
- 问题发生后的紧急处理原则
- 问题归类和分析
- 分析排查工具和命令
通常来说,最后的解决方式有两种,第一种是最普遍的,绝大部分的最终问题原因可以定位到代码层面,修改代码后问题解决。
第二种,调整某些JVM参数,缓解问题发生的频率和时间,但是治标不治本,所以本篇分析文档并未涉及JVM参数的优化调整。
三.紧急处理原则
问题发生后,第一时间是快速保留问题现场供后面排查定位,然后尽快恢复服务。保留现场的具体操作:
- 打印堆栈信息,命令行:
jstat -l 进程PID - 打印内存镜像,命令行:
jmap -dump:format=b,file=hprof 进程PID - 生成core文件,命令行:
gcore 进程PID - 保留gc日志文件
- 保留业务日志文件
- 查看JAVA堆内存运行分配:命令行:
jstat -gcutil 进程PID 1000 - 完成以上操作后,尽快重启JAVA进程或回滚,恢复服务。
四.问题归类和分析
当应用系统运行缓慢,页面加载时间变长,后台长时间无影响时,都可以参考以下归类的解决方法。绝大部分的JAVA程序运行时异常都是Full GC、OOM(java.lang.OutOfMemoryError)、线程过多。主要分这么几大类:
- 持续发生Full GC,但是系统不抛出OOM错误
- 堆内存溢出:
java.lang.OutOfMemoryError:Java heap space - 线程过多:
java.lang.OutOfMemoryError:unable to create new native thread - JAVA进程退出
- CPU占用过高
通常来说,可以用一些常用的命令行来打印堆栈、内存使用分配、打印内存镜像文件来分析,比如jstack、jstat、jmap等。但是某些时刻,还是需要引入更高阶的代码级分析工具(比如btrace)才能定位到具体原因。针对每一种问题,我会依据具体的case来详细说明解决方式。
五.分析排查工具和命令
问题排查,除了最重要的解决思路外,合理的运用工具也能达到事半功倍的效果,某些时候用好了工具,甚至能直接定位到导致问题的具体代码。
JDK自带工具
Jstat
实时查看gc的状况,通过jstat -gcutil 可以查看new区、old区等堆空间的内存使用详情,以及gc发生的次数和时间
https://docs.oracle.com/javase/9/tools/jstat.htm#JSWOR734
Jstack
很重要的命令,jstack可以用来查看Java进程里的线程都在干什么,对于应用没反应、响应非常慢等场景都有很大的帮助。几乎所有java问题排查时,我第一选择都是使用jstack命令打印线程信息。使用fastthread.io进行线程分析。
Jmap
jmap -dump用于保存堆内存镜像文件,供后续MAT或其他的内存分析工具使用。jmap -histo:live也可以强制执行full gc。
Jinfo
通常我用它来查看Java的启动参数
gcore
我通常会使用gcore命令来保留问题现场,速度非常快。某些时候执行jstack或jmap会报错,加-F也不行,这个时候就可以用gcore命令,gcore javapid 可以生成core文件,可以通过jstack和jmap命令从core文件里导出线程和内存镜像文件。
堆内存分析工具
MAT
eclipse官方推出的本地内存分析工具,下载链接是https://www.eclipse.org/mat/downloads.php,运行需要大量内存,从使用角度来讲,并不方便。我现在已经很少使用。
ZProfiler
阿里中间件出品的在线堆内存分析工具,链接是:http://zprofiler.alibaba-inc.com,不需要拷贝镜像文件,直接在线分析。
EagleEye-MProf
也是阿里中间件团队推出的,适用于复杂云环境的轻量级java堆内存分析工具,非常好用。在公共云或者专有云的机器上,运行的是客户的机器。由于权限或者网络的关系,我们很难去执行jmap进行heap dump,或者scp上传dump文件。这个工具可以直接在ECS上分析,而不用下载dump文件。
代码跟踪工具
Btrace
Java代码动态跟踪神器。少数的问题可以mat后直接看出,而多数会需要再用btrace去动态跟踪。比如排查线程创建过多的场景,通过btrace可以直接定位到哪段代码创建了大量线程。
比较麻烦的就是要自行编写脚本,不过现成的脚本也有不少,可以直接使用。
六.案例分析一:持续出现Full GC
处理原则
如果发现cms gc或full gc后,存活的对象始终很多,这种情况下可以通过jmap -dump来获取下内存dump文件,也可以通过gcore命令生成core文件,再用jmap从core里导出dump文件。然后通过MAT、ZProfile、EagleEye-MProf来分析内存镜像分布。如果还不能定位,最后使用btrace来定位到具体的原因。对于cms gc而言,还有可能会出现promotion failed或concurrent mode failure问题。
分析过程
1. 查看GC日志:
发现应用系统一直在做full gc,而且还有报错”concurrent mode failure”,这表示在执行gc过程中,有对象要晋升到旧生代,而此时旧生代空间不足造成的。

2. 查看应用访问日志:
有条很可疑的访问记录,响应时间特别长,达到了60S,直接超时了。

3. 查看JVM内存分配详情:
如何判断JVM垃圾回收是否正常,我通常会使用jstat命令,jstat是JDK自带的一个轻量级小工具。全称Java Virtual Machine statistics monitoring tool,它位于java的bin目录下,主要利用JVM内建的指令对Java应用程序的资源和性能进行实时的命令行的监控,包括了对Heap size和垃圾回收状况的监控。
可见,jstat是轻量级的、专门针对JVM的工具,非常适用。jstat工具特别强大,有众多的可选项,详细查看堆内各个部分的使用量,以及加载类的数量。使用时,需加上查看进程的进程id,和所选参数。
执行:cd $JAVA_HOME/bin中执行jstat,注意jstat后一定要跟参数。
具体命令行:jstat -gcutil 进程PID 1000
https://docs.oracle.com/javase/9/tools/jstat.htm#JSWOR734
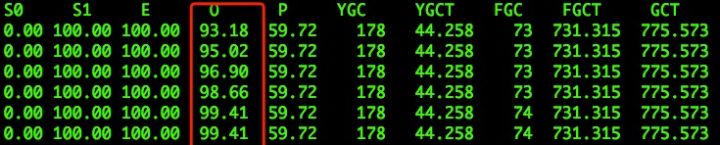
如图所示,发现Eden区、Old区都满了,此时新创建的对象无法存放,晋升到Old区的对象也无法存放,所以系统持续出现Full GC了。
4. 分析内存镜像:
这种问题比较直观,需要dump内存镜像,然后用MAT或者Zprofiler工具分析heapdump文件。
MAT(Memory Analyzer Tool),一个基于 Eclipse 的内存分析工具,是一个快速、功能丰富的 JAVA heap 分析工具,它可以帮助我们查找内存泄漏问题。
Zprofiler是阿里中间件团队推出的在线JAVA内存分析工具,不用在本地运行,访问http://zprofiler.alibaba-inc.com/即可。
保存内存镜像的命令:jmap -dump:format=b,file=hprof 进程PID,通常来讲这个文件会比较大,一般都会有好几个G。
用MAT或ZProfile分析结果如下,基本定位了问题的原因
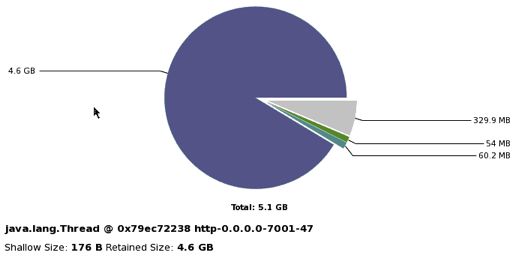
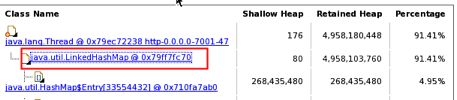
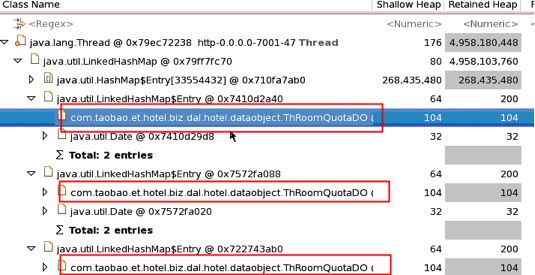
很明显,LinkedHashMap占用了91.41%的内存,里面有大量的ThRoomQuotaDO的引用对象,很有可能是死循环造成了这样的现象。不过要寻找真实原因,还得看看具体的代码。
5. 查看源代码
查询ThRoomQuotaDO类的源代码,发现了导致死循环的代码,如下:
代码段一:
1 | if(start == null || end == null || start.before(now)){ |
这里的start和end就是之前应用访问日志里的那条get请求带进来的,请求的url如下:

请注意start=2010-04-031061,本来这个start的值是不规范的,但代码还是通过SimpleDateFormat把start解析成的Date为(Fri Apr 15 00:00:00 CST 2095),所以不会进入代码段一的if块中去。
代码段二:
1 | Map roomQuotaMapFull = new LinkedHashMap(); |
这里就是最终导致full gc的代码:d.compareTo(hotelQuery.getEnd()) != 0,显然start和end是不相等的,所以陷入死循环中,以致把内存塞满了。
因此,最终的原因得到了定位,要解决起来那就很容易了。
6. 解决
代码段一:
修改导致问题的代码(标红处是修改后的)
1 | if(start == null || end == null || start.before(now))|| start.after(end)){ |
代码段二:
1 | for (Date d = hotelQuery.getStart();d.compareTo(hotelQuery.getEnd()) <= 0 ;d = CalendarUtil.addDate(d, 1)) { |
重新打包发布后,内存恢复正常,再也没有发生此类问题。
案例分析二:OOM:unable to create new native thread
处理原则
在日志中可能会看到java.lang.OutOfMemoryError: Unable to create new native thread,可以先统计下目前的线程数(例如ps -eLf | grep java -c),然后可以看看ulimit -u的限制值是多少,如线程数已经达到限制值,如限制值可调整,则可通过调整限制值来解决;如不能调限制值,或者创建的线程已经很多了,那就需要看看线程都是哪里创建出来的,首先用jstack命令打印线程堆栈信息,统计线程状态,然后通过btrace来查出是哪里创建的线程。
如果jstack执行失败的话,可以使用gcore命令生成core文件:gcore pid > core.**
然后再用jstack和jmap可以导出堆栈和内存镜像文件。
具体命令:jstack $JAVA_HOME/bin/java core.** > jstack.log
分析过程
1. 查看GC日志:
发现gc都正常,没有full gc,new区,old区都正常,确定不是heap堆出问题。
2. 查看应用访问日志:
发现业务日志中有很多错误:
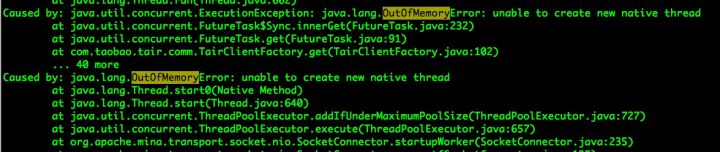
3. 查看线程堆栈:
查看jstack.log堆栈信息发现一共有8204个线程,其中blocked的有8169个,明显不正常。通过堆栈信息不能看出是什么导致创建了这么多线程,但是至少能确定导致oom的原因了:线程创建太多,且全部block了。下面就需要用btrace工具跟进分析具体是什么代码创建了这么多的线程。
4. 使用Btrace工具分析:
编写btrace脚本ThreadStart.java,内容如下:
1 | import static com.sun.btrace.BTraceUtils.*; |
执行命令:./btrace javapid ThreadStart.java > thread.log
查看thread.log,到这里可以确定问题所在了,基本上所有的线程都在这个类里创建:com.taobao.et.web.ie.module.action.IeOrderCheckAction.doMileageMeta
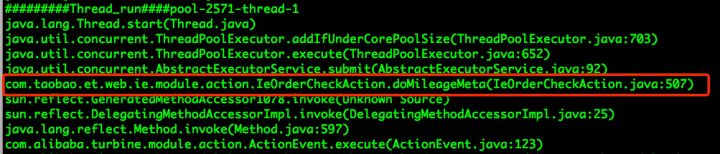
5. 查看源代码
从代码里可以看到,每次执行doMileageMeta都会创建一个线程池,但是没有shutdown释放资源。
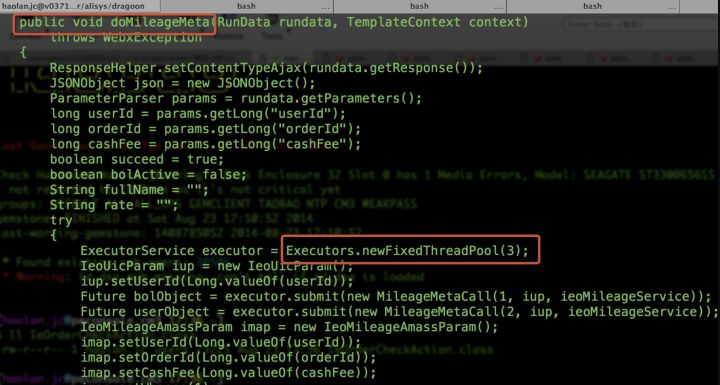
问题原因就清楚了:应用启动后,每次请求都会创建一个包含3个线程的线程池,但是从不释放资源,涨到8000多个以后,达到线程上限,抛出了unable to create new native thread。
6. 解决
修改代码:每次创建线程池后,调用shutdown方法来释放资源,具体代码就不帖出来了。
案例分析三:OOM:java heap space
处理原则
java.lang.OutOfMemoryError: java heap size也是常见的现象。最重要的是dump出内存,一种方法是通过在启动参数上增加-XX:+HeapDumpOnOutOfMemoryError。
另一种方法是在当出现OOM时,通过jmap -dump获取到内存dump,在获取到内存dump文件后,可通过MAT进行分析,但通常来说仅仅靠MAT可能还不能直接定位到具体应用代码中哪个部分造成的问题。
例如MAT有可能看到是某个线程创建了很大的ArrayList,但这样是不足以解决问题的,所以通常还需要借助btrace来定位到具体的代码。
案例分析四:Java进程退出
处理原则
对于Java进程退出,最重要的是要让系统自动生成coredump文件,需要设置ulimit -c unlimited,表示core文件为不限制大小,通常会加到java应用的启动脚本里。当进程crash发生时,找到coredump文件,core文件通常位于/应用部署目录/target (core文件一般在程序工作区产生)下。有可能的原因是代码中出现了无限递归或死循环,可通过jstack来提取出Java的线程堆栈,从而具体定位到具体的代码。
如果以上方法无效时,可以尝试dmesg命令,看看系统出了什么问题,有可能是系统主动杀掉了Java进程(例如内存超出限制)
分析过程
1.生成coredump文件
在将出现crash的服务器上打开ulimit,等待生成core文件,执行命令:ulimit -c unlimited。
2.分析coredump文件
执行命令:gdb -c $JAVA_HOME/bin/java coredump_file
键入:info threads —– 获取core文件中线程信息
其中*号前代表是crash时,当前正在运行的线程
即当前正在运行的线程为 9406
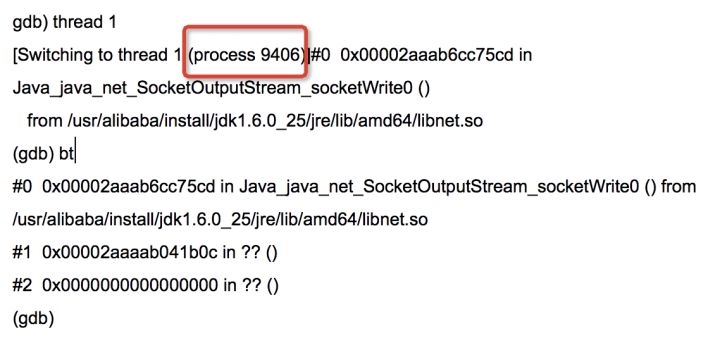
3.使用jstack命令分析core文件,获取指定线程id对应的代码信息
具体命令:jstack $JAVA_HOME/bin/java coredump_file > jstack.log,搜索刚才得到的线程编号 9406,发现问题如下:

原因就是代码里出现了无限递归,导致了爆栈。
案例分析五:CPU占用过高
处理原则
从经验上来说,有些时候是由于频繁cms gc或fgc造成的,在gc log是记录的情况下(-Xloggc:),可通过gc log看看,如果没打开gc log,可通过jstat -gcutil来查看,如是gc频繁造成的,则可跳到后面的内存问题 | GC频繁部分看排查方法。
如不是上面的原因,可使用top -H查看线程的cpu消耗状况,这里有可能会看到有个别线程是cpu消耗的主体,这种情况通常会比较好解决,可根据top看到的线程id进行十六进制的转换,用转换出来的值和jstack出来的java线程堆栈的nid=0x[十六进制的线程id]进行关联,即可看到此线程到底在做什么动作,这个时候需要进一步的去排查到底是什么原因造成的,例如有可能是正则计算,有可能是很深的递归或循环,也有可能是错误的在并发场景使用HashMap等。
分析过程
这里分享下如何查看具体导致CPU高的线程名称
- 找到最耗CPU资源的java进程PID。执行命令:
top获取cpu最高的pid - 查看哪个线程导致cpu过高。执行命令:
ps -mp 18588 -o THREAD,tid,time获取cpu最高的线程TID - 将找到的线程TID进行十六进制的转换
printf "%x\n" tid - 从堆栈文件里找到对应的线程名称
通过命令导出堆栈文件:jstack pid > jstack.log,根据上一步得到的16进制线程TID,搜索堆栈文件,即可看到此线程到底在做什么动作或者直接jstack pid |grep 16进制tid -A 30。