1、介绍
solr自带的几个分词器对中文支持并不好,所以需要使用第三方分词器对中文进行分词索引。
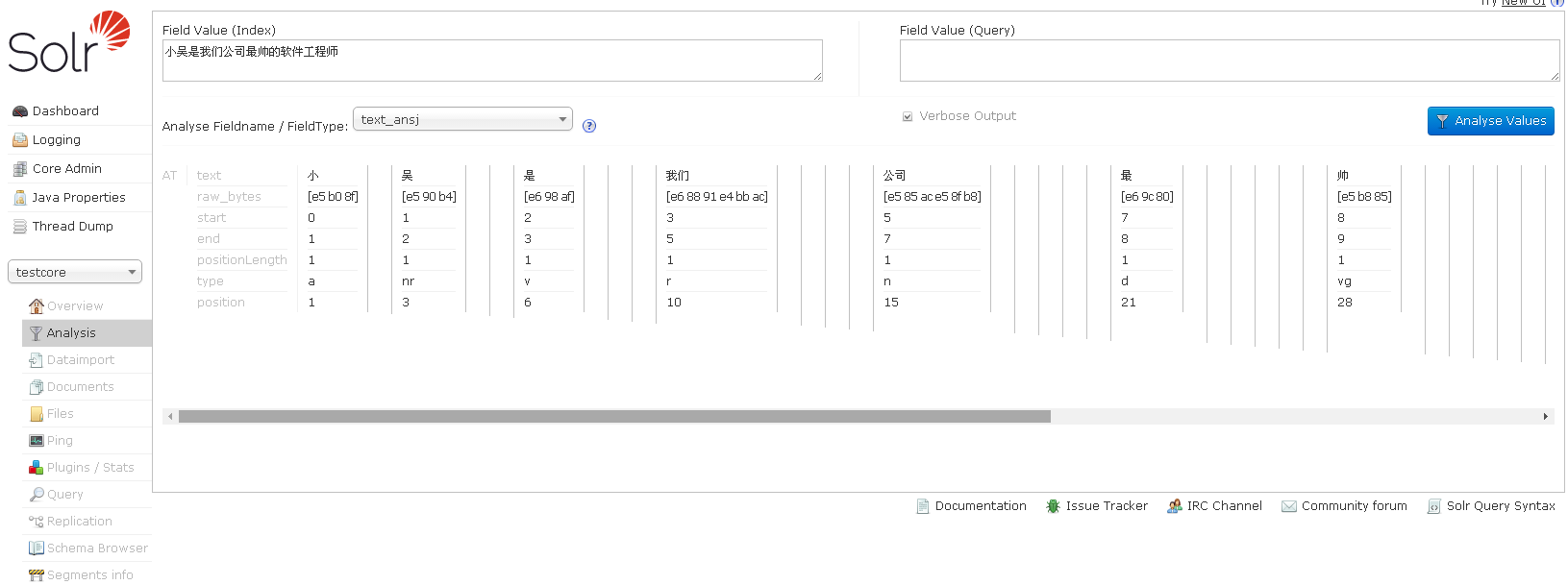
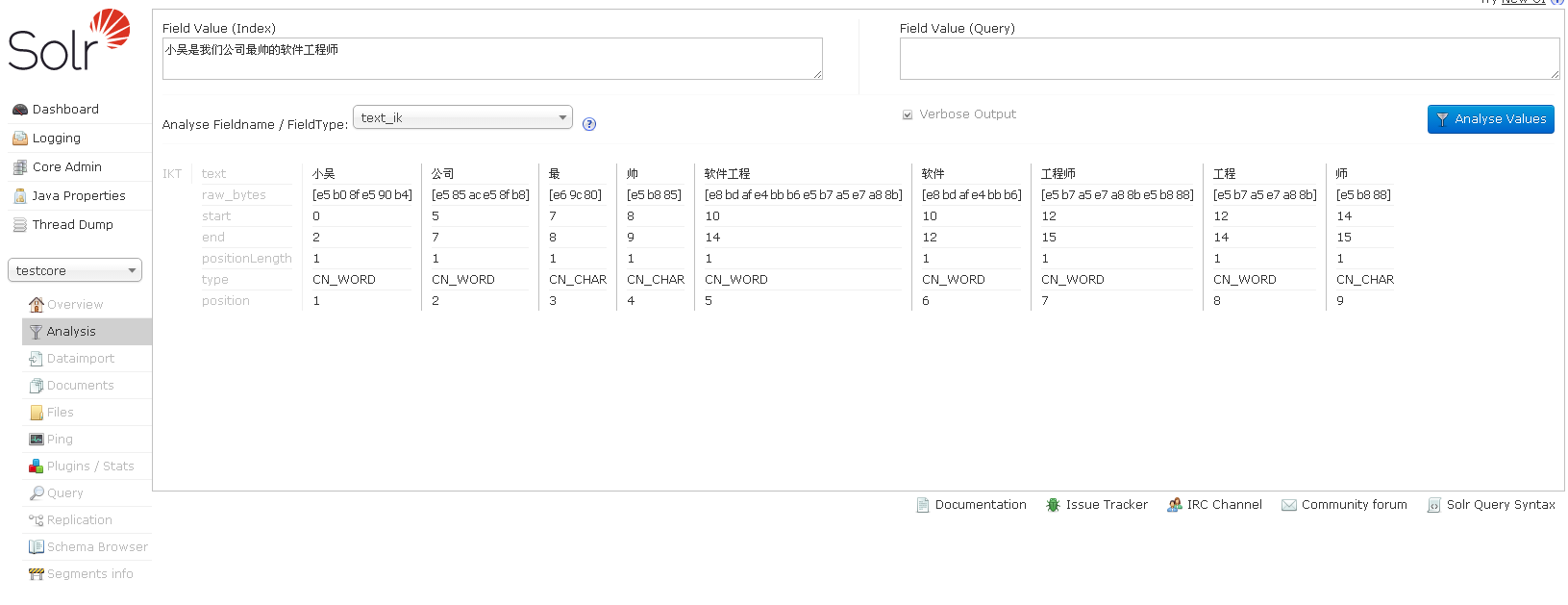
推荐的分词器有:ansj和ik,前者的效果更好。
注:目前发现ansj分词器索引内容大小超过65248字节时,会报异常,目前尚未找到解决办法
2、依赖
ansj_lucene5_plug-5.1.1.2.jar
ansj_seg-5.1.1.jar
ik-analyzer-solr5-5.x.jar
nlp-lang-1.7.2.jar
下载链接
3、配置
将以上四个jar包复制到solr安装路径下的server/solr-webapp/webapp/WEB-INF/lib/路径下
修改配置文件server/solr/核心/conf下的managed-schema,添加如下代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" />
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" />
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
</analyzer>
</fieldType>
<fieldType name="text_ansj" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="org.ansj.lucene.util.AnsjTokenizerFactory" isQuery="false" stopwords="/path/to/stopwords.dic"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.ansj.lucene.util.AnsjTokenizerFactory" stopwords="/path/to/stopwords.dic"/>
</analyzer>
</fieldType>
|
在managed-schema中为索引的字段添加分词器,例如
1
| <field name="TBPackageName" type="text_ansj" indexed="true" stored="true"/>
|
4、测试